
Agent harness: patrones de diseño para agentes de IA

Hay un patrón que se repite en los equipos que ya usan IA todos los días: la demo es
espectacular, pero el día a día no escala. Alguien le pide algo a un chat, copia la respuesta, la pega en otro sistema, detecta un error, vuelve al chat, re-explica todo el contexto… y así. El modelo es potente, pero el proceso sigue siendo artesanal.
La diferencia entre esa experiencia y un agente que completa tareas de principio a fin casi nunca está en el modelo. Está en todo lo que lo rodea: el agent harness.
En este artículo vamos a ver qué es un agent harness, qué patrones de diseño debería tener cualquiera —sin casarnos con ningún framework en particular— y por qué representa un salto de valor real frente a usar IA por chat.
¿Qué es un agent harness?
Un agent harness es la capa de software que rodea al modelo de lenguaje y lo convierte en un agente: le entrega herramientas para actuar sobre el mundo, le administra el contexto, ejecuta sus decisiones, verifica los resultados y aplica controles de seguridad.
Una analogía simple: el modelo es el motor; el harness es el resto del auto. Chasis, dirección, frenos, tablero. Un motor en un banco de pruebas puede ser impresionante, pero nadie llega a destino manejando un motor. Por eso dos productos construidos sobre el mismo modelo pueden comportarse de forma radicalmente distinta: la diferencia está en el harness.
El loop agéntico
El corazón de cualquier harness es un ciclo simple: recolectar contexto, decidir la próxima acción, ejecutarla con una herramienta, observar el resultado y repetir hasta cumplir el objetivo. Conceptualmente:
while not objetivo_cumplido and presupuesto_restante > 0:
contexto = preparar_contexto(estado, memoria)
decision = modelo.decidir(contexto, herramientas)
resultado = ejecutar(decision) # el harness actúa, no el modelo
estado = verificar_y_actualizar(resultado)El modelo decide; el harness ejecuta, observa y retroalimenta. Este patrón de razonar y actuar en ciclo es la base que formalizan trabajos como ReAct (Yao et al., 2023).
Y hay un detalle que no es opcional: el loop necesita criterios de término y presupuestos —máximo de iteraciones, tiempo, costo—. Un agente sin límites no es autónomo: es incontrolable.
El modelo no es el agente
Un LLM, por sí solo, recibe texto y produce texto. No lee tu base de datos, no ejecuta tus tests, no recuerda lo que pasó ayer. Las capacidades de un agente emergen del sistema completo: modelo \+ herramientas \+ memoria \+ verificación. Cuando ese sistema está mal diseñado, cambiar a un modelo más capaz arregla muy poco.
Chat vs. agent harness: por qué cambia el juego
Cuando trabajas por chat, el loop agéntico también existe… solo que el harness eres tú. Tú recolectas el contexto, tú copias y pegas, tú ejecutas, tú verificas, tú decides si seguir. Funciona para tareas puntuales, pero tiene techos claros:
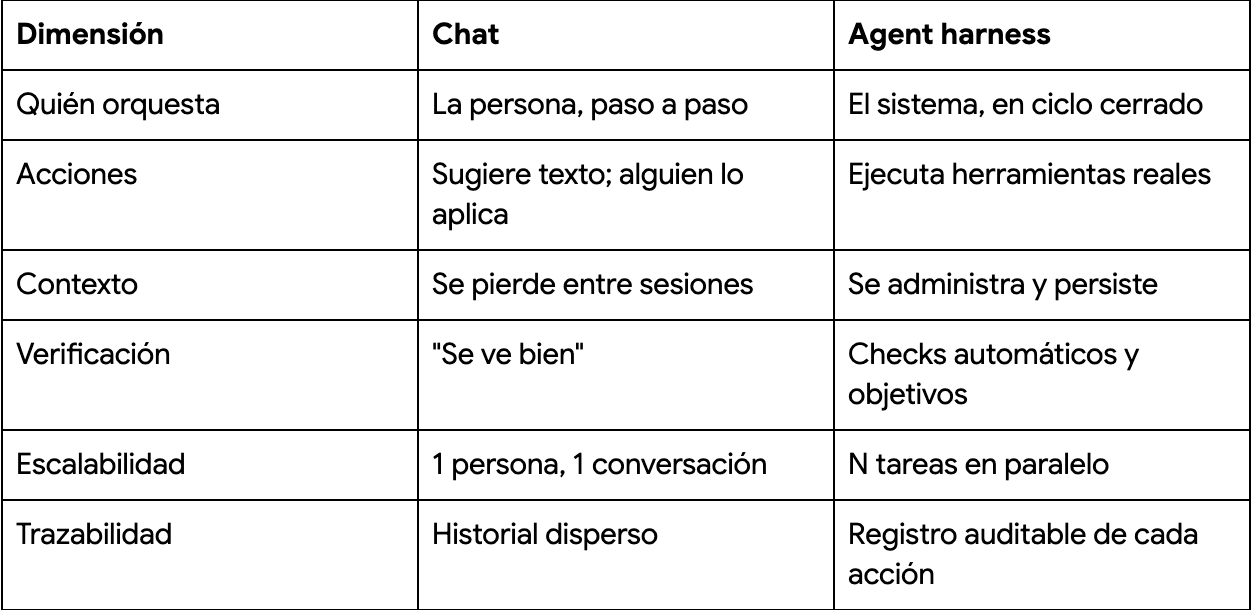
La diferencia de fondo es esta: el chat optimiza una conversación; el harness optimiza un resultado.
Por eso prácticas como el desarrollo guiado por especificaciones encajan tan bien con agentes: la spec define qué significa "correcto", y el harness es la maquinaria que ejecuta y verifica ese contrato sin que una persona tenga que mediar cada paso.
Patrones de núcleo de todo agent harness
Más allá del framework que elijas (o construyas), estos patrones aparecen en todos los harness serios. Los frameworks cambian cada trimestre; los conceptos, no.
Herramientas como contratos
Las herramientas son la interfaz del agente con el mundo: consultar una API, leer archivos, ejecutar código, crear un ticket. Diseñarlas es diseño de API: nombres claros, parámetros validados, descripciones sin ambigüedad y errores que expliquen qué salió mal y cómo corregirlo —porque el agente lee esos errores y se autocorrige—.
La investigación sobre uso de herramientas muestra que los modelos mejoran drásticamente cuando pueden delegar en sistemas externos lo que no deberían "adivinar" (Schick et al., 2023). Regla práctica: un agente es tan bueno como sus herramientas.
Ingeniería de contexto
La ventana de contexto es un recurso escaso, y su calidad se degrada cuando la llenas de ruido. Un buen harness no vuelca todo "por si acaso": carga información justo a tiempo, resume o compacta lo viejo cuando la tarea se alarga y mantiene visible solo lo relevante para la decisión actual (Anthropic, 2025).
El contexto es al agente lo que la RAM a un proceso: administrarlo bien es la diferencia entre fluidez y colapso.
Memoria y estado fuera del contexto
Lo que importa no puede vivir solo en la conversación. Planes, decisiones, progreso y aprendizajes deben persistir fuera del modelo: archivos, una base de datos, incluso un simple plan.md. Esto permite retomar tareas largas, sobrevivir reinicios y compartir estado entre sesiones o entre agentes, una idea central en las arquitecturas cognitivas para agentes de lenguaje (Sumers et al., 2023).
Si el conocimiento queda atrapado en el chat, se pierde. Si vive en artefactos, se acumula.
Patrones de confiabilidad y control
Los patrones anteriores hacen que el agente funcione. Estos hacen que puedas confiar en él. Y son exactamente los que seguridad y compliance van a preguntar antes de aprobar cualquier agente en producción.
Verificación automática
El patrón con mayor retorno de todos: darle al agente una forma objetiva de saber si lo que hizo está bien. Tests que se ejecutan, linters, validación de esquemas, comparación contra criterios de aceptación.
Con feedback verificable, el agente itera contra la realidad y se corrige solo. Sin él, itera contra su propia opinión. Esta es la diferencia más grande con el chat, donde la verificación depende del ojo —y del cansancio— de una persona.
Autonomía graduada: permisos y human-in-the-loop
La autonomía no es un interruptor, es una perilla. Un buen harness distingue acciones reversibles (leer, buscar, proponer) de acciones sensibles (escribir en producción, enviar un correo, gastar dinero) y exige aprobación humana para las segundas.
Sumado a ejecución en sandbox y permisos granulares por herramienta, esto permite delegar cada vez más a medida que el agente demuestra confiabilidad, en lugar de apostar toda la autonomía desde el día uno.
Observabilidad y trazabilidad
Cada decisión, cada llamada a herramienta y cada resultado debe quedar registrado. Sin trazas no puedes depurar un agente, medir su tasa de éxito, controlar costos ni auditar por qué hizo lo que hizo.
La observabilidad convierte al agente de caja negra en proceso gobernable: puedes responder "¿qué pasó?" con evidencia, no con hipótesis.
Aplicación en empresas: del piloto al proceso productivo
¿Por qué esto importa más allá de lo técnico? Porque los patrones de un agent harness son exactamente lo que separa un piloto entretenido de un proceso de negocio confiable.
- Escalabilidad: un agente con harness ejecuta decenas de tareas en paralelo, sin depender de la habilidad de prompting de cada persona. El conocimiento del proceso vive en el sistema, no en individuos.
- Calidad consistente: los loops de verificación producen resultados repetibles. Una migración de código, un triage de tickets o un control de calidad de datos cumplen el mismo estándar a las 3 de la tarde y a las 3 de la mañana.
- Reducción de costos: la automatización deja de limitarse a "generar texto" y alcanza procesos completos de varios pasos: soporte, generación y ejecución de pruebas, conciliación de datos, actualización de documentación.
- Gobernanza y seguridad: permisos, aprobaciones y auditoría integrados hacen viable usar IA en entornos regulados. No son un agregado posterior: están en el diseño.
Un ejemplo concreto: un agente que migra servicios a una nueva versión de un framework. Por chat, una persona pide fragmentos y los pega durante días. Con harness, el agente lee el repositorio, planifica en un archivo persistente, modifica el código, corre la suite de tests después de cada cambio, revierte lo que falla, registra cada decisión y pide aprobación antes del merge.
Mismo modelo. Valor completamente distinto.
Buenas prácticas al adoptar (o construir) un agent harness
- Evalúa frameworks por conceptos, no por marca. Sea cual sea la herramienta de moda, pregúntale: ¿cómo maneja el loop y sus límites? ¿Cómo define herramientas? ¿Cómo administra contexto y memoria? ¿Qué verificación, permisos y trazas ofrece? Si no responde bien estas preguntas, la marca no importa.
- Empieza simple. Un loop con tres herramientas bien diseñadas y verificación automática supera a una arquitectura multiagente compleja sin checks e infinitos mds inentendibles. La complejidad se agrega cuando una métrica lo justifica (Anthropic, 2024).
- Diseña desacoplado del modelo. Los modelos mejoran y cambian de precio cada pocos meses. Si tu harness permite intercambiarlos, cada avance del mercado es una mejora gratis para tu sistema.
- Invierte en evaluación. Define qué significa "tarea exitosa", arma un set de casos de prueba y mide antes de aumentar la autonomía. Sin evals, escalar un agente es escalar un riesgo.
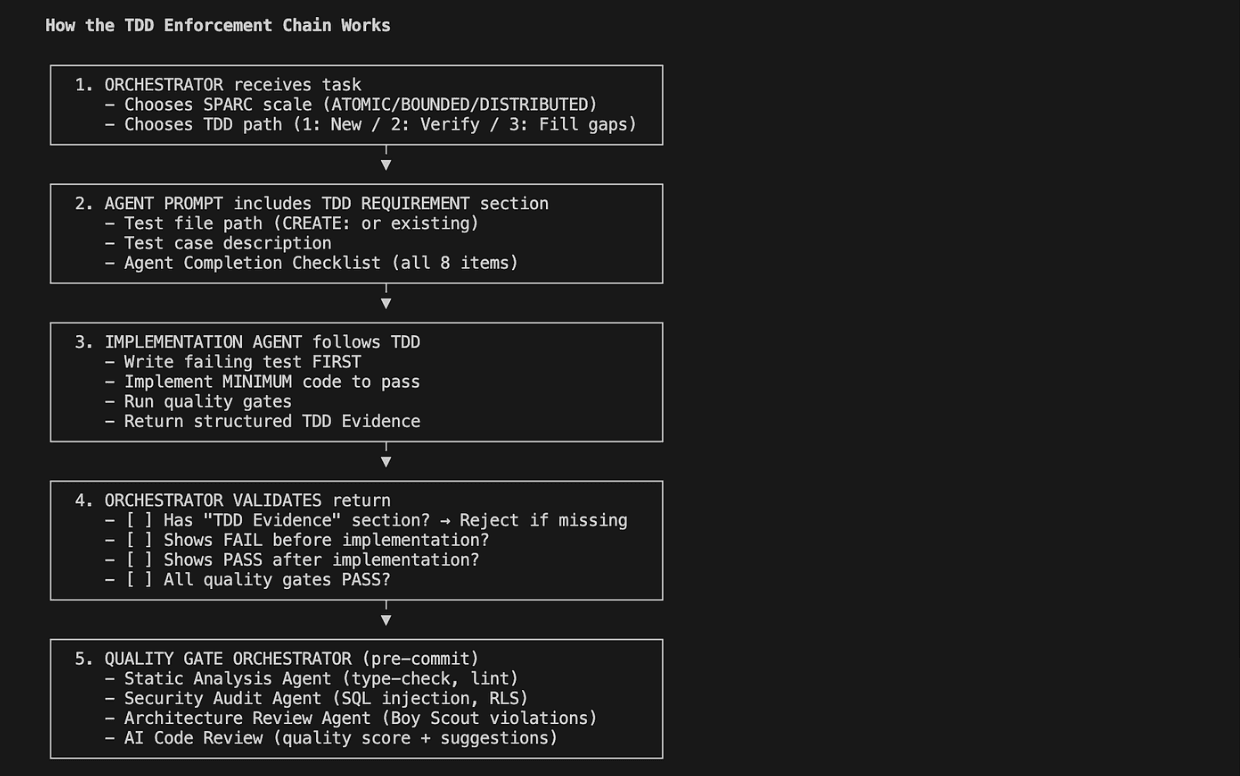
- Trata prompts y herramientas como código. Versionado, revisión y pruebas. El comportamiento del agente es parte de tu sistema, no un texto suelto.
Conclusión
La conversación pública sobre IA gira alrededor de los modelos, pero el valor en producción se decide en otra parte: en el agent harness. El loop con límites, las herramientas como contratos, la ingeniería de contexto, la memoria persistente, la verificación automática, la autonomía graduada y la observabilidad no son features de un framework: son los patrones que convierten un modelo que conversa en un sistema que entrega resultados.
El chat seguirá siendo útil para explorar. Pero cuando el objetivo es operar —con calidad repetible, control y auditoría—, el harness es la diferencia.
La implementación de un agent harness bien diseñado no solo mejora la eficiencia técnica, sino que también permite a las empresas automatizar procesos completos, reducir costos y escalar soluciones de forma segura y sostenible. En Kranio contamos con equipos especializados que han implementado este tipo de soluciones en proyectos empresariales reales.
👨💻 Si tu empresa busca implementar este tipo de soluciones, puedes contactarnos en 👉 www.kranio.io
Referencias
Anthropic. (2024). Building effective agents. https://www.anthropic.com/research/building-effective-agents
Anthropic. (2025). Effective context engineering for AI agents. https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Zettlemoyer, L., Cancedda, N., & Scialom, T. (2023). Toolformer: Language models can teach themselves to use tools. arXiv. https://arxiv.org/abs/2302.04761
Sumers, T. R., Yao, S., Narasimhan, K., & Griffiths, T. L. (2023). Cognitive architectures for language agents. arXiv. https://arxiv.org/abs/2309.02427
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023). ReAct: Synergizing reasoning and acting in language models. arXiv. https://arxiv.org/abs/2210.03629
Alan Buscaglia (Gentlemann Programming, 2026\)
Gentleman Programming \- YouTube
Gentleman-Programming/gentle-ai
Entradas anteriores

Spec-driven coding con IA: guia practica para equipos
Descubre cómo el Spec-Driven Coding ayuda a los equipos a usar IA para desarrollar software con más control, mejores pruebas y menos deuda técnica.

Cómo elegir entre HTTP REST y GraphQL para tu API
Descubre las diferencias entre HTTP REST y GraphQL y aprende cuál arquitectura API elegir según escalabilidad, rendimiento y flexibilidad.
