
Spec-driven coding con IA: guia practica para equipos
Spec-driven coding con IA: guia practica para equipos
Hay una pregunta que aparece cada vez más en equipos que ya usan asistentes de IA para programar: si el modelo puede escribir código en segundos, cuál es exactamente el trabajo del desarrollador?
La respuesta fácil es decir que ahora programar consiste en saber pedir. Pero esa respuesta se queda corta. Un buen prompt ayuda, por supuesto. White et al. (2023) muestran que los patrones de prompt permiten estructurar interacciones con LLMs, imponer reglas y mejorar la calidad de la salida generada. Pero en contextos reales, donde hay seguridad, mantenibilidad, deuda técnica, integraciones y usuarios esperando que el sistema no se rompa, pedir bien no alcanza.
El problema no es que la IA escriba código. El problema es que muchas veces lo hace sin una especificación suficientemente precisa de lo que significa “correcto”.
Que es spec-driven coding
Spec-driven coding es una forma de trabajar donde la especificación deja de ser un documento decorativo y pasa a ser el centro operativo del desarrollo. Antes de pedir código, el equipo explícita:
- Qué problema se quiere resolver.
- Qué comportamiento observable debe cumplir la solución.
- Qué casos no debe aceptar.
- Que restricciones arquitectonicas, de seguridad y de dominio no se pueden violar.
- Qué pruebas van a demostrar que la implementación es correcta.
En otras palabras: el modelo no recibe solamente una intención, recibe un contrato.
Esta diferencia parece pequeña, pero cambia todo. En vibe coding, el ciclo suele ser: pedir, ejecutar, mirar si funciona, corregir, repetir. En este enfoque, el ciclo es: especificar, convertir la especificación en checks verificables, generar o modificar código, ejecutar pruebas, revisar desviaciones y actualizar la especificación si el aprendizaje lo justifica.
La IA puede acelerar la escritura del código.
La especificación decide si ese código pertenece al sistema.
Por que ahora importa más que antes
Para 2024, el estudio sobre GPT-4 de Bubeck et al. ya mostraba que los LLAMas habían alcanzado capacidades impresionantes para tareas de programación: un modelo capaz de resolver problemas complejos en múltiples dominios, incluyendo coding, con un salto importante respecto de generaciones previas (Bubeck et al., 2023). En ese momento, la conclusión era clara: el desarrollo de software había cambiado de velocidad.
Dos años después, en 2026, esa sensación se volvió todavía más intensa. Los modelos son más rápidos, las herramientas están mejor integradas al IDE y la generación de código dejó de ser una curiosidad para convertirse en parte cotidiana del flujo de trabajo de muchos equipos.
Pero velocidad no es dirección.
Cuando una herramienta puede producir una implementación plausible casi de inmediato, el cuello de botella deja de ser la escritura y pasa a ser la validación. El riesgo silencioso es aceptar código que compila, pasa una prueba superficial y parece razonable, pero que no respeta una regla de negocio, no sigue la arquitectura real, omite un edge case o introduce una decisión que nadie pidió.
Ese es el lugar donde la especificación se vuelve una práctica de ingeniería, no una ceremonia.
TDD como antecedente
Este enfoque no aparece de la nada. Tiene una deuda clara con Test-Driven Development.
Beck (2002) formulaba TDD como una disciplina donde el desarrollador avanza escribiendo primero una prueba que falla, luego el código mínimo para hacerla pasar y finalmente refactorizando. La idea de fondo sigue siendo potente: antes de construir, hacemos explícita una expectativa.
La diferencia es que con IA esa expectativa necesita expandirse. Ya no basta con un test unitario aislado. Muchas veces necesitamos especificar también contratos de API, invariantes de dominio, restricciones de datos, políticas de seguridad, límites de performance, convenciones de arquitectura y criterios de aceptación legibles para negocio.
TDD nos enseñó a no confiar en la memoria del programador.
Esta práctica nos enseña a no confiar en la intuición estadística del modelo.
IA multiagente y testing
Los frameworks multiagente refuerzan esta idea. Chat Dev propone agentes especializados que colaboran en fases como diseño, codificación y testing mediante comunicación estructurada (Qian et al., 2024). Agent oder va en una dirección similar: separa roles como programador, diseñador de pruebas y ejecutor de pruebas, usando feedback iterativo para mejorar la generación de código (Huang et al., 2024).
Estos trabajos muestran algo relevante para equipos reales: cuando la IA participa en más partes del ciclo de desarrollo, la coordinación se vuelve tan importante como la generación.
Y la coordinación necesita artefactos compartidos.
Una buena especificación cumple ese rol. No es solo un input para el modelo. Es el punto de encuentro entre producto, arquitectura, QA, seguridad y desarrollo. Permite que un agente genera código, que otro derive pruebas, que otro revise cumplimiento y que una persona pueda auditar la decisión sin reconstruir todo desde cero.
Si el prompt es una conversación, la especificación es memoria institucional.
La investigación sobre LLMs aplicados a testing también apunta en esta dirección. Wang et al. (2024) revisan 102 estudios sobre uso de LMs en pruebas de software y muestran que las tareas más representativas incluyen preparación de casos de prueba y reparación de programas. Es decir, la IA puede ayudar mucho a producir pruebas, ampliar escenarios y encontrar caminos que un equipo podría pasar por alto.
Pero eso no significa que podamos delegar el criterio de calidad.
Una suite generada desde una especificación pobre solo automatizar una comprensión incompleta. Una suite generada desde una especificación ambigua puede incluso dar una falsa sensación de seguridad: muchas luces verdes, poca garantía real.
Por eso el orden importa:
- Primero se define el comportamiento esperado.
- Luego se derivan pruebas y checks.
- Después se genera o modifica el código.
- Finalmente se revisa si la solución cumple la especificación y si la especificación era suficientemente buena.
La IA puede participar en cada paso, pero no debería borrar la frontera entre “esto funciona” y “esto era lo que necesitábamos construir”.
Spec-driven coding en la practica
Un flujo de trabajo puede ser tan simple como este:
1. Escribir una spec pequeña y concreta
No un documento eterno. Una especificación útil para desarrollo debería caber en el contexto de trabajo y responder preguntas operativas:
- Objetivo de negocio.
- Alcance incluido y excluido.
- Estados del sistema.
- Entradas y salidas esperadas.
- Reglas de validación.
- Errores conocidos.
- Criterios de aceptación.
- Restricciones técnicas.
Ejemplo práctico: si el equipo necesita agregar descuentos por volumen a un checkout B2B, la spec no debería decir solo "aplicar descuentos a clientes grandes". Debería decir: "si una empresa compra 50 o más licencias, aplicar 10% de descuento; si compra 200 o más, aplicar 18%; el descuento no se acumula con cupones promocionales; el total debe guardarse en centavos como entero; toda regla nueva debe quedar cubierta por tests unitarios y de integración", en la figura 1 podemos ver un ejemplo tangible del prompt.
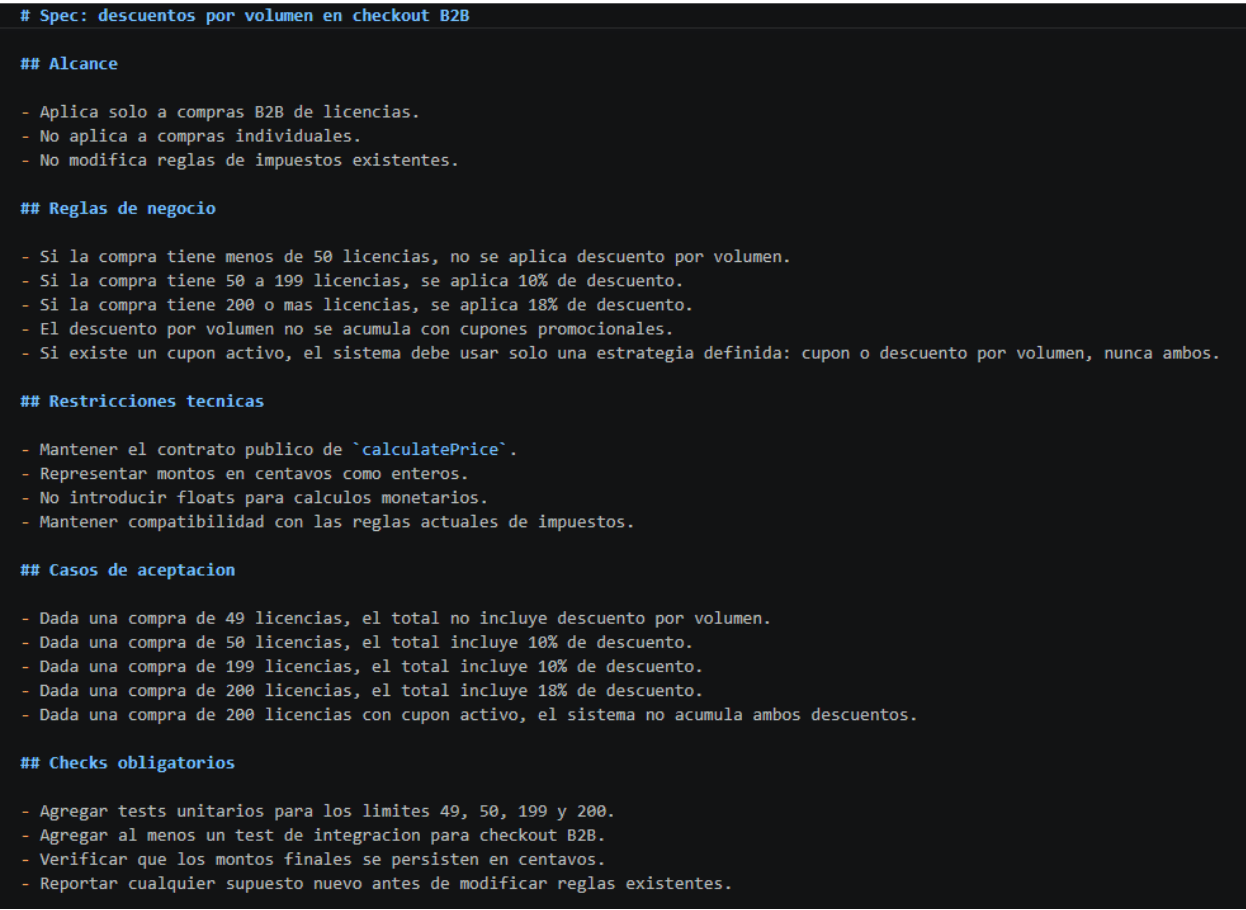
2. Convertir la spec en ejemplos verificables
Cada regla importante debería tener al menos un ejemplo. Si el sistema calcula precios, necesitamos casos con descuentos, impuestos, redondeos y excepciones. Si procesamos postulaciones, necesitamos estados válidos, transiciones válidas y permisos por rol.
La IA puede ayudar a proponer esos ejemplos, pero el equipo debe revisarlos como revisará requisitos.
3. Generar, criticar y actualizar
En vez de “crear esta feature”, el prompt debería decir: implementa esta feature cumpliendo esta especificación, sin cambiar estos contratos, usando estos patrones, manteniendo compatibilidad con estos tests y explicando cualquier supuesto nuevo.
Aquí los prompt patterns son útiles: ayudan a encuadrar rol, formato, verificación, restricciones y pasos de razonamiento operacional (White et al., 2023). Pero el valor no está en adornar el prompt; está en reducir la superficie de ambigüedad.
Ejemplo práctico: el prompt al agente podría ser: "Implementa la regla de descuentos por volumen definida en pricing-spec.md. No cambies el contrato público de calculatePrice. Mantiene montos en centavos, agrega tests para los casos de 49, 50 y 200 licencias, y antes de editar revisa si existen reglas previas de cupones en el módulo de pricing", en la figura 2 vemos el resultado de este ejercicio de actualización.
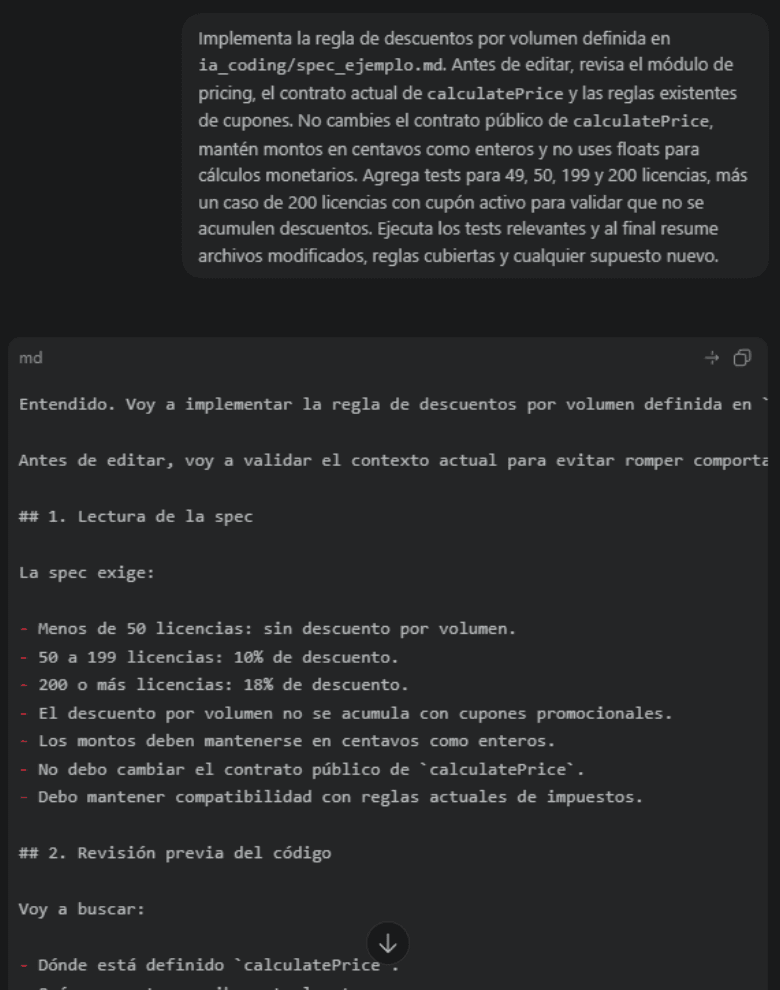
Una práctica sana es pedirle al asistente que busque contradicciones entre spec, tests y código. No para reemplazar la revisión humana, sino para hacer más barata la primera ronda de fricción.
Preguntas utiles:
- ¿Qué regla de la spec no está cubierta por pruebas?
- ¿Qué comportamiento implementado no aparece en la spec?
- ¿Qué supuesto hiciste sin confirmación?
- ¿Qué caso podría romper esta solución?
- ¿Qué parte del código contradice la arquitectura existente?
Una especificación no es una piedra. Si durante la implementación aparece una regla nueva, un constraint técnico o una decisión de producto, esta información debe volver al documento. De lo contrario, el conocimiento queda atrapado en el chat, en el diff o en la cabeza de alguien.
Y ahí vuelve el mismo problema de siempre: el equipo pierde contexto.
4. Convertir la spec en una skill del agente
Cuando una especificación deja de ser experimental y empieza a repetirse en varios tickets, conviene transformarla en una skill o instrucción reutilizable para el agente. En vez de copiar el mismo contexto en cada conversación, el equipo documenta el procedimiento, las reglas de dominio, los archivos relevantes, los checks obligatorios y los criterios de salida en un artefacto estable que el agente pueda invocar automáticamente.
Esto permite que el conocimiento operativo no dependa de la memoria del chat. Si cada cambio de pricing, authentication, reporting o integración debe cumplir ciertas invariantes, la skill puede recordarle al agente como analizar el problema, que rutas revisar, que pruebas ejecutar y qué decisiones no puede tomar sin validación humana.
La spec describe que significa "correcto" para una feature. La skill convierte ese criterio en comportamiento recurrente del agente.
Ejemplo práctico: si el pricing cambia todas las semanas, el equipo puede convertir esa spec en una skill llamada pricing-rules. El usuario no necesita pegar la misma explicación en cada ticket, por ejemplo usando Codex puede pedirle que use /skill-creator para crear una skill con el flujo esperado, tal cual como se aprecia en la figura 3, el resultado será una skill que el agente puede reutilizar.
En esa skill, el equipo documenta que Codex debe leer docs/pricing-spec.md, revisar src/pricing, validar compatibilidad con cupones, ejecutar la suite de pricing y reportar cualquier supuesto nuevo antes de modificar código. Luego, en un ticket futuro, basta con pedir algo como: "Usa la skill pricing-rules para implementar este cambio de descuentos". Codex carga esas instrucciones automáticamente y trabaja con el contexto correcto desde el inicio.
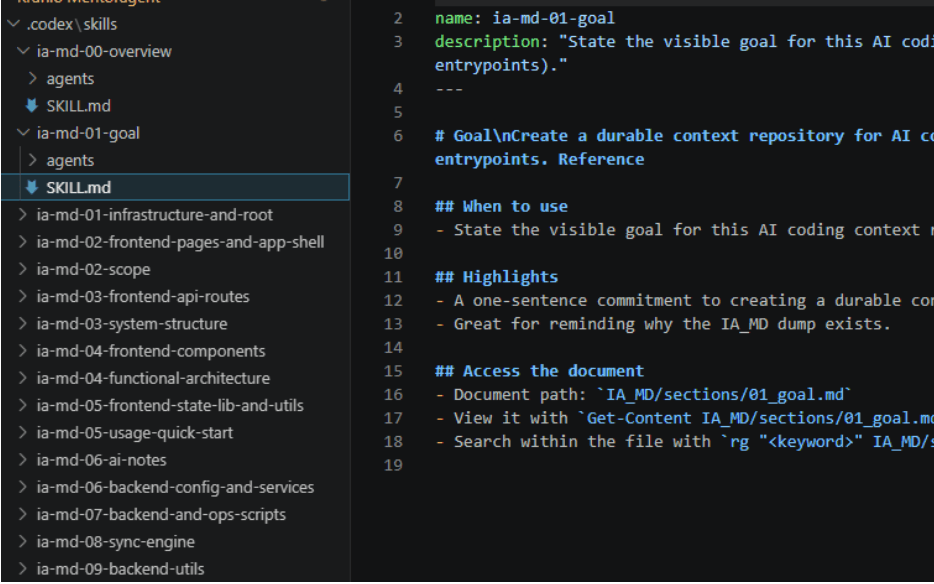
Aplicación en empresas
En empresas, este enfoque importa porque el costo real del software no está solo en escribirlo. Está en mantenerlo, auditar, integrarlo con otros sistemas y cambiarlo sin romper procesos críticos.
Cuando la especificación queda conectada con pruebas, criterios de aceptación y restricciones técnicas, la IA puede acelerar tareas repetitivas sin dejar al equipo a ciegas. Eso mejora la eficiencia, reduce el trabajo y hace más fácil escalar el desarrollo entre varios equipos, agentes o proveedores.
También tiene un beneficio de negocio: permite discutir una feature desde evidencia verificable. Producto puede revisar si el comportamiento esperado está cubierto, QA puede derivar escenarios, arquitectura puede validar límites y desarrollo puede implementar con menos ambigüedad.
Buenas prácticas y recomendaciones
La promesa incómoda de este enfoque es que no hace que la IA parezca más mágica. Hace lo contrario: la vuelve más gobernable.
Eso puede sentirse menos espectacular que escribir una frase y ver aparecer una aplicación completa. Pero en equipos que construyen software serio, la espectacularidad no es el objetivo. El objetivo es poder responder preguntas difíciles:
- ¿Por que se implemento asi?
- ¿Qué requisito cubre esta parte?
- ¿Qué prueba demuestra que funciona?
- ¿Qué riesgo aceptamos?
- ¿Qué decisión debe revisar una persona?
Cuando esas respuestas existen, la IA deja de ser una caja de sorpresas y se convierte en una capacidad de producción bajo control técnico.
Conclusion
La próxima etapa del desarrollo con IA no se va a definir solo por modelos más capaces. Se va a definir por equipos capaces de especificar mejor.
Spec-driven coding no trata de escribir documentos por nostalgia. Trata de darle a la IA un marco suficientemente claro para que su velocidad no destruya el criterio del equipo.
La implementación de spec-driven coding no solo mejora la eficiencia técnica, sino que también permite a las empresas optimizar sus procesos, reducir costos y escalar soluciones de forma segura y sostenible. En Kraneo contamos con equipos especializados que han implementado este tipo de soluciones en proyectos empresariales reales.
Si tu empresa busca implementar este tipo de soluciones, puedes contactarnos en www.kranio.io.
Referencias
Beck, K. (2002). Test-driven development: By example. Three Rivers Institute. Material local: TDD.pdf. Referencia publica equivalente: https://www2.cs.uh.edu/~rsingh/documents/software_design/TDD.pdf
Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., Lee, P., Lee, Y. T., Li, Y., Lundberg, S., Nori, H., Palangi, H., Ribeiro, M. T., & Zhang, Y. (2023). Sparks of artificial general intelligence: Early experiments with GPT-4. arXiv. https://arxiv.org/abs/2303.12712. Material local: 2303.12712v5.pdf
Huang, D., Zhang, J. M., Luck, M., Bu, Q., Qing, Y., & Cui, H. (2024). AgentCoder: Multi-agent-based code generation with iterative testing and optimisation. arXiv. https://arxiv.org/abs/2312.13010. Material local: 2312.13010v3.pdf
Qian, C., Liu, W., Liu, H., Chen, N., Dang, Y., Li, J., Yang, C., Chen, W., Su, Y., Cong, X., Xu, J., Li, D., Liu, Z., & Sun, M. (2024). ChatDev: Communicative agents for software development. arXiv. https://arxiv.org/abs/2307.07924. Material local: 2307.07924v5.pdf
Wang, J., Huang, Y., Chen, C., Liu, Z., Wang, S., & Wang, Q. (2024). Software testing with large language models: Survey, landscape, and vision. arXiv. https://arxiv.org/abs/2307.07221. Material local: 2307.07221v3.pdf
White, J., Fu, Q., Hays, S., Sandborn, M., Olea, C., Gilbert, H., Elnashar, A., Spencer-Smith, J., & Schmidt, D. C. (2023). A prompt pattern catalog to enhance prompt engineering with ChatGPT. arXiv. https://arxiv.org/abs/2302.11382. Material local: 2302.11382v1.pdf
Entradas anteriores
Prompt Injection en IA: cómo asegurar tu infraestructura
Descubre qué es el Prompt Injection en IA, cómo funcionan los ataques más recientes y qué estrategias implementar para proteger agentes, copilotos y sistemas basados en LLMs.
¿RabbitMQ (el rey de las colas) o Apache Kafka (el gigante de los eventos)?
Conoce las diferencias entre RabbitMQ y Apache Kafka, sus casos de uso y las novedades de 2026 para elegir la mejor solución de mensajería para tu arquitectura.
