
Caché en aplicaciones RESTful: cómo mejorar la velocidad de las APIs
En sistemas modernos basados en APIs, el rendimiento es un factor crítico para garantizar una buena experiencia de usuario. Cada solicitud a una API puede implicar consultas a bases de datos, cálculos complejos o comunicación con otros servicios. Cuando el volumen de tráfico aumenta, estos procesos pueden generar latencias significativas.
Una de las estrategias más efectivas para mejorar el rendimiento es la implementación de caché. El caché permite almacenar temporalmente respuestas o datos frecuentemente solicitados, reduciendo la necesidad de recalcular o consultar la base de datos en cada petición.
En este artículo exploraremos los principales retos al implementar caché en APIs RESTful, así como las mejores prácticas para aprovecharlo correctamente.
¿Qué es el caché?
La caché es un mecanismo de almacenamiento temporal que guarda datos frecuentemente utilizados para evitar recuperarlos cada vez de una fuente principal, como un servidor o una base de datos. Este proceso reduce el tiempo de respuesta y mejora el rendimiento general de las aplicaciones web. Ahora bien, dependiendo de dónde se almacenen estos datos en caché, podemos hablar de caché en el lado del cliente o caché en el lado del servidor.
Retos comunes al implementar caché en APIs RESTful
1. Datos obsoletos
Uno de los principales desafíos del caché es evitar que los usuarios reciban información desactualizada.
Cuando una API guarda una respuesta en caché y los datos cambian en la base de datos, existe el riesgo de que las próximas solicitudes sigan recibiendo la versión antigua. Esto puede ser problemático en sistemas donde la información cambia con frecuencia, como plataformas de comercio electrónico o aplicaciones financieras.
Por ejemplo, si una API devuelve información de productos y el precio cambia, un caché mal gestionado podría seguir mostrando el precio anterior durante cierto tiempo.
2. Definir qué endpoints deben usar caché
No todas las operaciones en una API deberían almacenarse en caché.
Generalmente, las operaciones GET son las candidatas ideales porque recuperan información sin modificarla. En cambio, las operaciones POST, PUT o DELETE suelen modificar datos, por lo que requieren estrategias especiales de invalidación del caché.
Identificar qué endpoints se benefician realmente del caché es clave para evitar inconsistencias o complejidad innecesaria.
3. Control de invalidación del caché
El famoso problema en ingeniería de software: cuándo invalidar el caché.
Si se invalida demasiado rápido, se pierde el beneficio del caché.
Si se invalida demasiado tarde, los usuarios podrían recibir información incorrecta.
Encontrar el equilibrio correcto depende del tipo de datos y del comportamiento del sistema.
Soluciones prácticas y mejores prácticas
1. Aprovechar los encabezados HTTP de caché
Las APIs RESTful pueden usar los mecanismos de caché integrados en HTTP para mejorar el rendimiento sin necesidad de infraestructura adicional.
Algunos encabezados importantes incluyen:
Cache-Control
Permite definir cómo y cuánto tiempo puede almacenarse una respuesta.
ETag
Permite validar si un recurso ha cambiado desde la última solicitud.
Last-Modified
Indica la última fecha en que un recurso fue actualizado.
Con estos encabezados, los clientes o proxies pueden reutilizar respuestas almacenadas sin necesidad de consultar nuevamente al servidor.
2. Implementar caché en memoria o distribuido
Para APIs con alto tráfico, una práctica común es utilizar sistemas de caché dedicados como:
- Redis
- Memcached
Estos sistemas permiten almacenar respuestas o datos procesados en memoria, lo que reduce significativamente el tiempo de respuesta de las APIs.
Por ejemplo, una API que consulta información de usuario desde una base de datos puede almacenar el resultado en Redis durante algunos minutos, evitando consultas repetidas a la base de datos.
3. Utilizar el patrón Cache-Aside
Uno de los patrones más utilizados en APIs es Cache-Aside, que funciona de la siguiente manera:
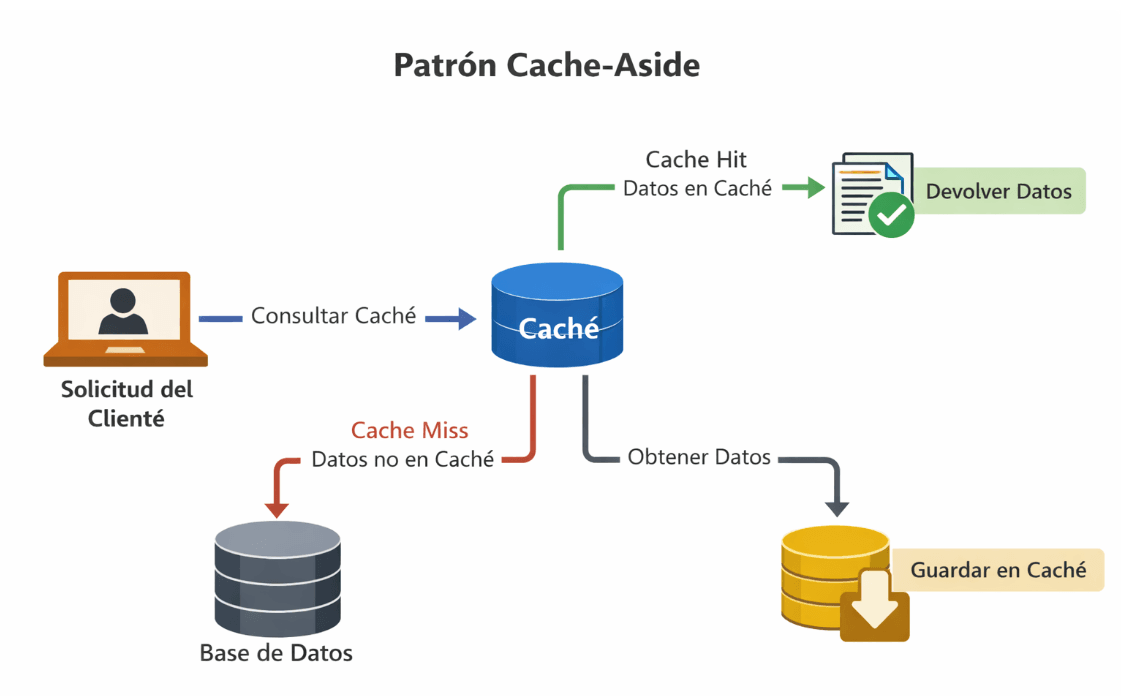
- La aplicación recibe una solicitud.
- Primero consulta el caché.
- Si los datos están disponibles (cache hit), se devuelven inmediatamente.
- Si no están (cache miss), se consultan en la base de datos.
- Luego se guardan en el caché para futuras solicitudes.
Este patrón permite mantener un equilibrio entre rendimiento y control de los datos almacenados.
4. Definir tiempos de expiración adecuados (TTL)
El TTL (Time-To-Live) determina cuánto tiempo un dato permanece en caché antes de eliminarse automáticamente.
Elegir un TTL adecuado depende del tipo de información:
- Datos que cambian poco: TTL más largo
- Datos dinámicos: TTL más corto
Esto ayuda a evitar información obsoleta mientras se mantienen los beneficios del caché.
5. Monitorear el rendimiento del caché
El caché debe monitorearse constantemente para garantizar que realmente esté mejorando el rendimiento del sistema.
Algunas métricas importantes incluyen:
- Cache hit rate: porcentaje de solicitudes atendidas desde el caché.
- Latencia de la API: tiempo de respuesta de las solicitudes.
- Uso de memoria del caché.
Herramientas de monitoreo permiten identificar si el caché está configurado correctamente o si requiere ajustes.
Casos de éxito en el uso de caché y microservicios
Caso 1: Netflix y la optimización de su sistema global
Netflix, uno de los principales usuarios de arquitecturas basadas en microservicios, utiliza ampliamente el sistema de caché distribuido EVCache para manejar miles de millones de solicitudes diarias. Gracias a este enfoque, han logrado mantener una baja latencia incluso durante picos de tráfico, como el lanzamiento de nuevas temporadas de series populares.
El uso de un caché distribuido no solo ha permitido a Netflix escalar su sistema globalmente, sino que también ha mejorado la experiencia del usuario al reducir significativamente los tiempos de carga.
Caso 2: Twitter y la coherencia de datos
Twitter enfrenta el desafío de mantener la coherencia de datos en tiempo real para miles de millones de usuarios activos. Para ello, utilizan una combinación de sistemas de caché y bases de datos distribuidas, junto con estrategias avanzadas de invalidez de caché.
Esta combinación les permite garantizar que los usuarios vean contenido actualizado casi al instante, sin sacrificar el rendimiento del sistema.
Caso 3: Shopify y la escalabilidad en comercio electrónico
Shopify, una plataforma líder en comercio electrónico, utiliza caché para manejar grandes volúmenes de datos relacionados con catálogos de productos, información de usuarios y transacciones. Al implementar Redis como su solución de caché principal, Shopify ha podido escalar su sistema para soportar miles de tiendas en línea, manteniendo una experiencia de usuario fluida incluso durante eventos como el Black Friday.
Conclusión
El caché es una herramienta fundamental para mejorar el rendimiento de las APIs RESTful. Al reducir consultas repetidas a la base de datos y reutilizar respuestas previamente generadas, es posible disminuir significativamente la latencia y mejorar la escalabilidad de los sistemas.
Sin embargo, implementar caché correctamente requiere considerar aspectos como la coherencia de los datos, la estrategia de invalidación y el monitoreo continuo del sistema.
Aplicando prácticas como el uso de encabezados HTTP, sistemas de caché en memoria, patrones como Cache-Aside y tiempos de expiración adecuados, los equipos de desarrollo pueden construir APIs más rápidas, eficientes y escalables.
En un ecosistema donde las APIs son el núcleo de muchas aplicaciones modernas, optimizar su rendimiento mediante caché puede marcar una gran diferencia en la experiencia del usuario final.
👉 ¿Tu arquitectura está preparada para escalar sin afectar el rendimiento?
En Kranio diseñamos soluciones robustas, eficientes y listas para alto tráfico.
Contáctanos y llevemos tu sistema al siguiente nivel.
Entradas anteriores

Cómo implementar un proxy para bases de datos con PgBouncer: guía paso a paso
Aprende a implementar un proxy para bases de datos con PgBouncer. Mejora el rendimiento, reduce conexiones y escala PostgreSQL fácilmente.

Agent harness: patrones de diseño para agentes de IA
Descubre qué es un Agent Harness y los patrones que permiten convertir modelos de IA en agentes capaces de ejecutar tareas, verificar resultados y escalar procesos empresariales.
