
CAG en LLMs: cómo reducir latencia y costos en IA
Si estás trabajando con modelos de lenguaje en producción, probablemente ya conoces ese momento incómodo: el usuario hace una pregunta, la aplicación consulta una base vectorial, trae fragmentos de documentos, los mete al prompt, y recién ahí el modelo responde. Funciona, sí. Pero cada una de esas etapas suma latencia, costos y puntos donde algo puede salir mal.
En ese camino me topé con un enfoque que vale la pena conocer: Cache-Augmented Generation (CAG).
En este blog quiero contarte qué es CAG, por qué está ganando tracción y en qué escenarios puede cambiarte la vida. Y sí, también quiero ser honesto: un buen RAG sigue siendo absolutamente necesario para muchos casos. No es reemplazar, es sumar una herramienta más a la caja.
¿Qué es CAG, en simple?
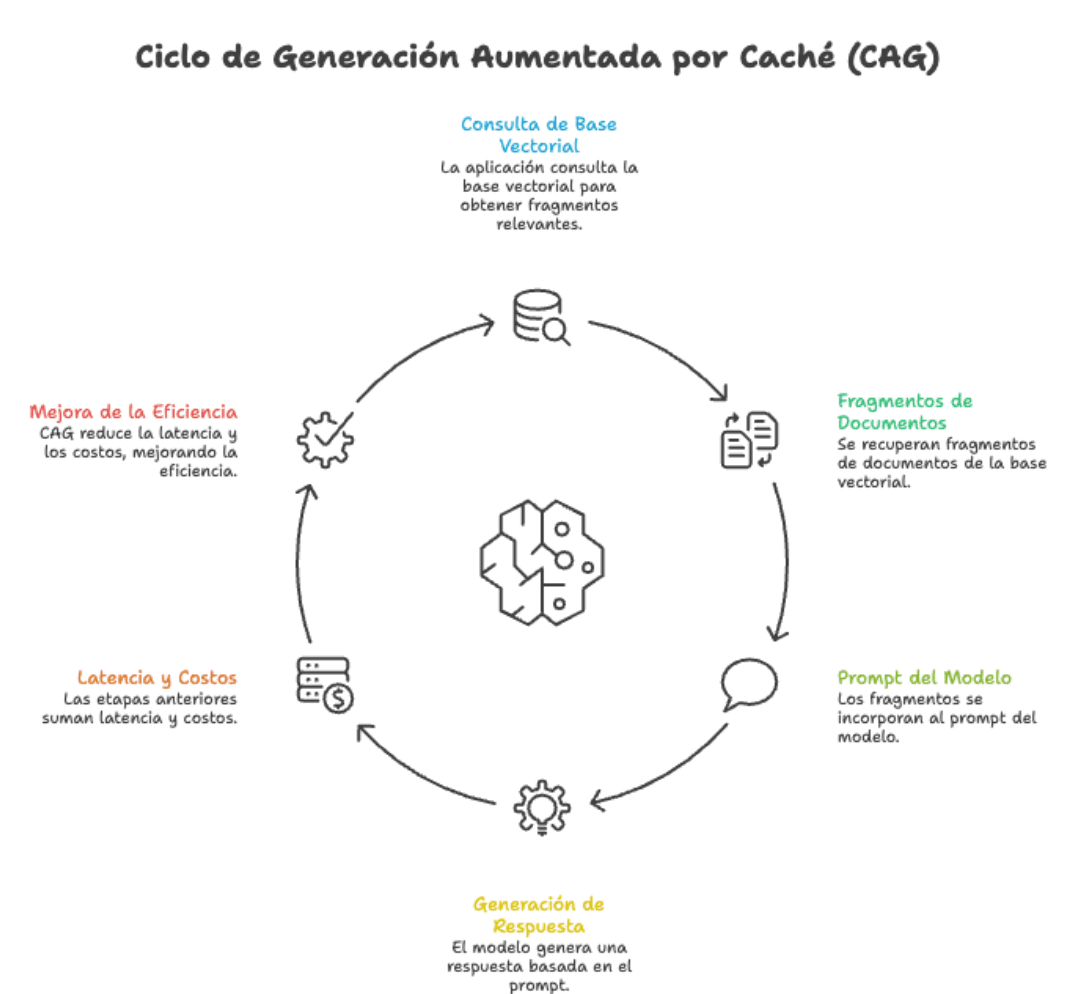
CAG parte de una idea directa: en lugar de buscar información cada vez que llega una pregunta, precargamos todo el conocimiento relevante dentro del contexto del modelo una sola vez y guardamos el estado interno del LLM (lo que se conoce como KV cache, o caché de llaves y valores de atención).
Cuando llega una consulta del usuario, el modelo ya "tiene en la cabeza" toda la documentación. No hay búsqueda vectorial, no hay ranking de resultados, no hay riesgo de traer el chunk equivocado. Solo: query → respuesta.
La técnica fue formalizada en el paper "Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks" y aprovecha una realidad que hasta hace poco no existía: los modelos de lenguaje modernos con ventanas de contexto significativamente extendidas que hoy nos permiten meter cientos de páginas de texto sin despeinarnos.
Las bondades de CAG
1. Velocidad que se siente
Este es el punto que más impacta en producción. Al eliminar la etapa de retrieval, las respuestas son casi instantáneas. Tareas complejas de pregunta-respuesta que antes tomaban 94.35 segundos ahora toman solo 2.33 segundos. Un incremento de velocidad de hasta 40x en ciertos benchmarks.
Para un chatbot interno, un asistente de onboarding o un help desk automatizado, esa diferencia entre "espera tres segundos" y "respuesta inmediata" es la diferencia entre un producto que la gente usa y uno que abandonan después de la segunda consulta.
2. Arquitectura más simple, menos piezas que mantener
Con RAG tradicional necesitas: una base vectorial, un modelo de embeddings, una estrategia de chunking, un pipeline de ingesta, un reranker (idealmente), y toda la observabilidad alrededor de eso. Cada componente es un lugar donde algo puede fallar.
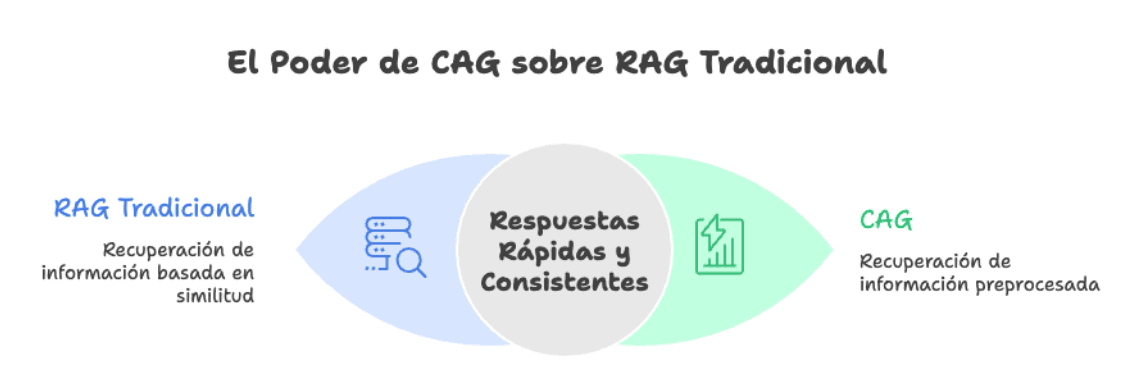
CAG, en cambio, reduce todo a: documentación preprocesada + KV cache + LLM. Elimina la necesidad de bases vectoriales, stores de embeddings o servicios externos de retrieval. Menos infraestructura, menos costos fijos, menos superficie para debuggear un martes a las 11 de la noche.
3. Respuestas más consistentes
Uno de los problemas clásicos de RAG es que la misma pregunta, formulada de dos formas distintas, puede traer chunks distintos y dar respuestas distintas. Con CAG eso desaparece: todas las consultas se responden contra el mismo contexto completo, lo que mejora muchísimo la consistencia. Para casos como políticas internas, documentación de productos o respuestas regulatorias, esto es oro.
4. Cero errores de retrieval
RAG puede fallar silenciosamente: trae el chunk equivocado, el modelo responde con confianza, y nadie se da cuenta hasta que un usuario lo reporta. CAG elimina esa categoría entera de errores. Si la respuesta está en los documentos precargados, el modelo la tiene disponible en todo momento. No depende de que un algoritmo de similitud haya rankeado bien.
5. Razonamiento multi-documento más natural
Cuando una pregunta requiere conectar información de varios documentos (multi-hop reasoning), RAG sufre: tiene que traer los chunks correctos de cada fuente y esperar que el modelo los relacione bien. CAG, al tener todo el corpus presente, razona sobre el conocimiento como un todo integrado. Esto se nota especialmente en preguntas complejas tipo "¿cómo se relaciona la política X con el procedimiento Y cuando aplica el escenario Z?".
6. Costos predecibles
Al eliminar las llamadas a servicios de embeddings y bases vectoriales, y al aprovechar el caché, los costos por consulta bajan y se vuelven mucho más predecibles. El costo grande se paga una vez, al precomputar el KV cache, y después cada query es comparativamente económica.
¿Dónde brilla CAG?
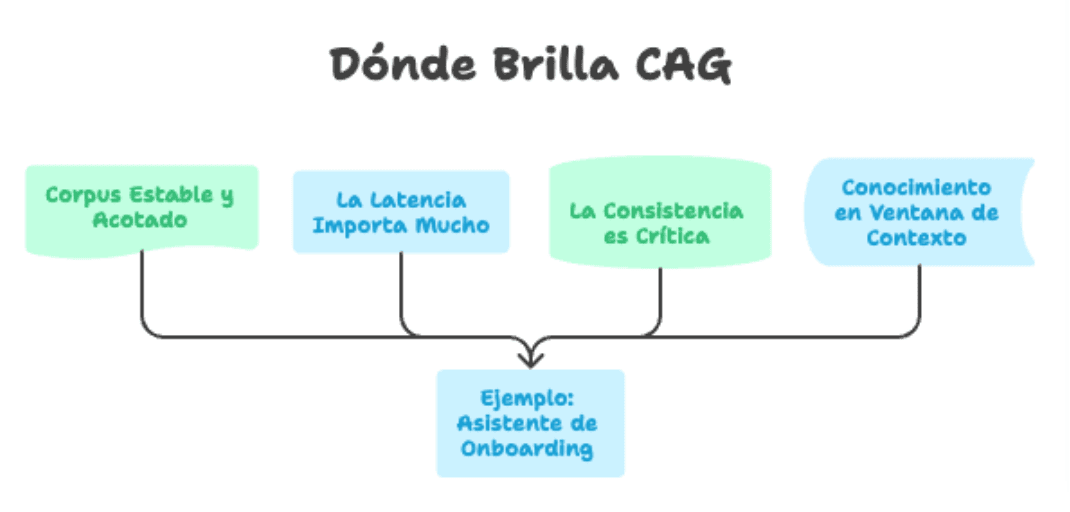
No todos los casos de uso son iguales. CAG se luce especialmente cuando:
- El corpus es estable y acotado. Manuales de producto, políticas internas, documentación técnica de una versión específica, marcos regulatorios, FAQs empresariales.
- La latencia importa mucho. Asistentes en tiempo real, bots de voz, experiencias conversacionales donde cada segundo cuenta.
- La consistencia es crítica. Respuestas legales, compliance, soporte de primer nivel, información corporativa oficial.
- El conocimiento cabe en la ventana de contexto. Con modelos que hoy soportan 128k, 200k o incluso 1M de tokens, esto cubre una cantidad enorme de casos reales.
En un proyecto típico de asistente de onboarding para una empresa, por ejemplo, toda la documentación relevante probablemente no pase de 80-100 páginas. Eso entra cómodo en el contexto de los modelos actuales, y el perfil de uso es el ideal: conocimiento estable, muchas consultas repetitivas, necesidad de respuesta rápida.
Pero ojo: un buen RAG sigue siendo necesario
Acá viene la parte honesta. CAG no es una bala de plata, y en Kranio creemos que ignorar RAG sería un error estratégico. Hay escenarios donde RAG no solo sigue siendo relevante, sino que es claramente la mejor opción:
Cuando el conocimiento es dinámico
Si tu información cambia todos los días, catálogos de productos, inventarios, tickets de soporte recientes, noticias, datos operacionales. CAG te obliga a recalcular el KV cache cada vez, lo que anula sus ventajas de velocidad. RAG, con su capacidad de indexar incrementalmente, está hecho para esto.
Cuando el corpus es masivo
CAG depende de que todo quepa en el contexto. Si tu base de conocimiento son millones de documentos, gigabytes de texto, historiales completos de clientes, ahí no hay contexto que alcance. RAG sigue siendo la herramienta correcta para navegar océanos de información y traer justo lo que importa.
Cuando necesitas trazabilidad fina
RAG te da, por diseño, la capacidad de decir "esta respuesta viene de este chunk de este documento". Esa trazabilidad es clave en casos regulados, auditorías y cualquier escenario donde citar la fuente no es opcional.
Cuando el dominio tiene muchas preguntas raras
Si tus usuarios hacen consultas muy variadas sobre nichos muy específicos de un corpus enorme, RAG con una buena estrategia de chunking y un reranker decente va a superar a CAG, que estaría cargando mucho contexto irrelevante para cada query.
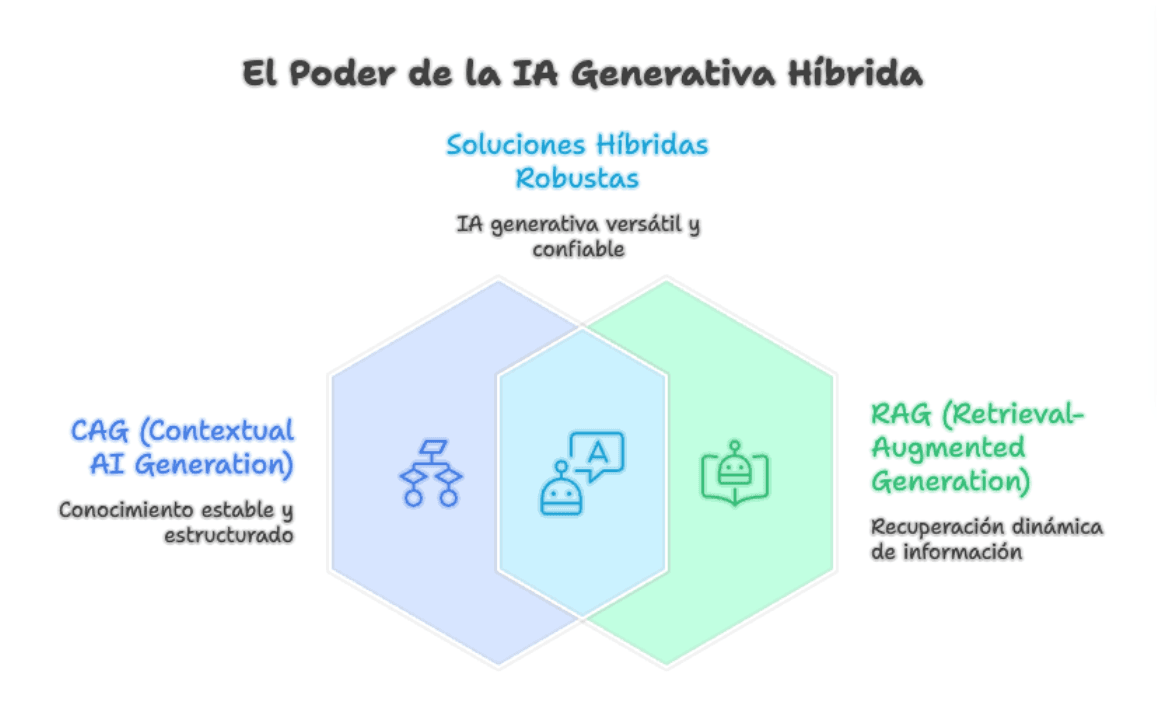
El futuro: arquitecturas híbridas
La discusión real no es "CAG o RAG". Es "¿qué combinación de ambos resuelve mejor mi problema?".
Ya estamos viendo patrones híbridos donde se precarga un contexto base con CAG (las políticas, los procesos, la documentación estable) y se usa RAG para casos específicos: buscar en tickets históricos, consultar datos transaccionales, traer información recién actualizada. Lo mejor de los dos mundos.
Un buen RAG bien diseñado con chunking inteligente, embeddings afinados al dominio, reranking y observabilidad sigue siendo la base sobre la cual se construyen las soluciones robustas de IA generativa. CAG es una evolución que potencia ciertos casos, no una excusa para bajar la vara en el diseño del retrieval.
En conclusión
CAG es una herramienta potente para cuando tu conocimiento es estable, acotado y la latencia importa. Te da velocidad, consistencia, menos infraestructura y menos errores de retrieval. Para muchos productos conversacionales y asistentes internos, puede ser exactamente la pieza que faltaba.
Pero la pregunta correcta no es "¿CAG o RAG?". Es "¿cuál es el diseño de arquitectura que mejor resuelve el problema de negocio, considerando cómo cambia el conocimiento, cuánto dura el contexto, y qué espera el usuario?".
Y responder esa pregunta bien con criterio de ingeniería, no con modas es justamente el tipo de desafío que en Kranio nos encanta resolver junto a nuestros clientes.
¿Estás evaluando IA generativa para tu empresa?
En Kranio diseñamos e implementamos soluciones de IA generativa adaptadas al contexto real de cada cliente desde la estrategia de arquitectura (RAG, CAG, híbridos) hasta el despliegue productivo y la operación. Si quieres conversar sobre cómo aplicar esto en tu organización, hablemos.
Entradas anteriores
Prompt Injection en IA: cómo asegurar tu infraestructura
Descubre qué es el Prompt Injection en IA, cómo funcionan los ataques más recientes y qué estrategias implementar para proteger agentes, copilotos y sistemas basados en LLMs.
¿RabbitMQ (el rey de las colas) o Apache Kafka (el gigante de los eventos)?
Conoce las diferencias entre RabbitMQ y Apache Kafka, sus casos de uso y las novedades de 2026 para elegir la mejor solución de mensajería para tu arquitectura.
