
Introducción a Data Science: Tipos de Datos y Roles Clave en Proyectos
Los proyectos de Data Science o ciencia de datos constituyen todos aquellos desarrollos donde se extraen datos de diversas fuentes, se manipulan y se visualizan para poder realizar análisis.
Para que estos proyectos sean construidos se debe entender el negocio del cliente junto con los datos que posee para poder levantar una solución que entregue valor a la organización y les permite tomar decisiones.
Sobre esta serie y artículo
Este es el primer artículo de la serie: “Data Science”. Cada artículo se puede leer independiente del orden ya que el contenido está separado por distintas etapas que , a pesar de tener una fuerte conexión se pueden entender individualmente. Cada publicación busca dar luz sobre los procesos que se llevan a cabo en la industria y que podrían ayudarte a decidir si tu organización puede contratar un servicio para migrar tus datos a la nube o aprender acerca de cómo funciona el desarrollo de este tipo de proyectos en caso de que seas estudiante. En esta primera parte hablaremos sobre el valor de los datos y los roles que desempeñan los clientes, los usuarios y los desarrolladores en los proyectos de Data Science.
Los datos
Los datos son toda aquella información que es útil para una empresa, las organizaciones pueden acceder hoy a muchísima información. Esto abarca data interna de la organización, data externa de clientes y data externa de la industria o competencia. Las empresas que tienen sus operaciones digitalizadas y por ende generan datos que pueden capturados, procesados y analizados.
Para poder trabajar con datos primero es necesario almacenarlos, para hacer esto contamos con varias alternativas. Los servicios de cómputo en la nube como Google Cloud Platform o Amazon Web Services (aunque hay otros) resultan sumamente eficientes y rentables, ya que cada uno, nos proporciona una variedad de servicios que nos ayudan con el propósito de almacenar datos con eficiencia y seguridad.
El valor de los datos
Para poder obtener valor de los datos debemos capturar, almacenar y estructurarlos de una manera en que se puedan tomar decisiones de negocio. La data no se puede usar solo para analizar situaciones anteriores o actuales, si no también para realizar predicciones y tomar acciones inteligentes. Esto significa que después de capturar la data se debe encontrar una forma de poder sacar verdadero valor de ella.
Una vez capturamos, identificamos o habilitamos una fuente de datos, debemos almacenarla. Podemos diferenciar el almacenamiento de datos en dos sistemas de almacenamientos distintos que explicaremos a continuación.
Data Warehouse vs Data Lake
Tanto los servicios de data warehouse como los data lake apuntan a solucionar lo mismo: almacenar grandes cantidades de datos. Su diferencia principal radica en que los data lake por su parte están pensados para almacenar data sin procesar (raw data). Mientras que el data warehouse almacena información estructurada, que ya se encuentra filtrada y que previamente ya ha sido procesada para poder llegar a la estructura que posee la data ya almacenada en el mismo data warehouse.
Data estructurada vs no estructurada
Al momento de almacenar datos, nos podemos encontrar con dos formatos:
Data estructurada: Se trata de data altamente organizada, pueden ser registros de clientes, tablas o datos con formato tabular y otra data que tiende a ser cuantitativa. La ventaja de este tipo de formato de datos es que puede ser fácilmente almacenada y administrada en bases de datos. Hay que considerar que este tipo de datos son generados al construir modelos y estructuras que permitan a los datos irse acumulando en forma ordenada. Este tipo de información es almacenada en Data Warehouses.
Data no estructurada: Se trata de data que no está organizada y se destaca por que tiende a ser cualitativa, contiene información sin definir y viene en muchos formatos. Ejemplos de este tipo de data son: Imágenes, audio y archivos PDF. Este tipo de información se almacena en Data Lakes.
Cuantitativa: Es toda aquella información que se puede medir.
Cualitativa: Es toda aquellas información que no se puede medir y para la cual se deben crear escalas de medición o modelos.
A continuación podemos ver una figura que describe las diferencias entre la data estructurada y la no estructurada.
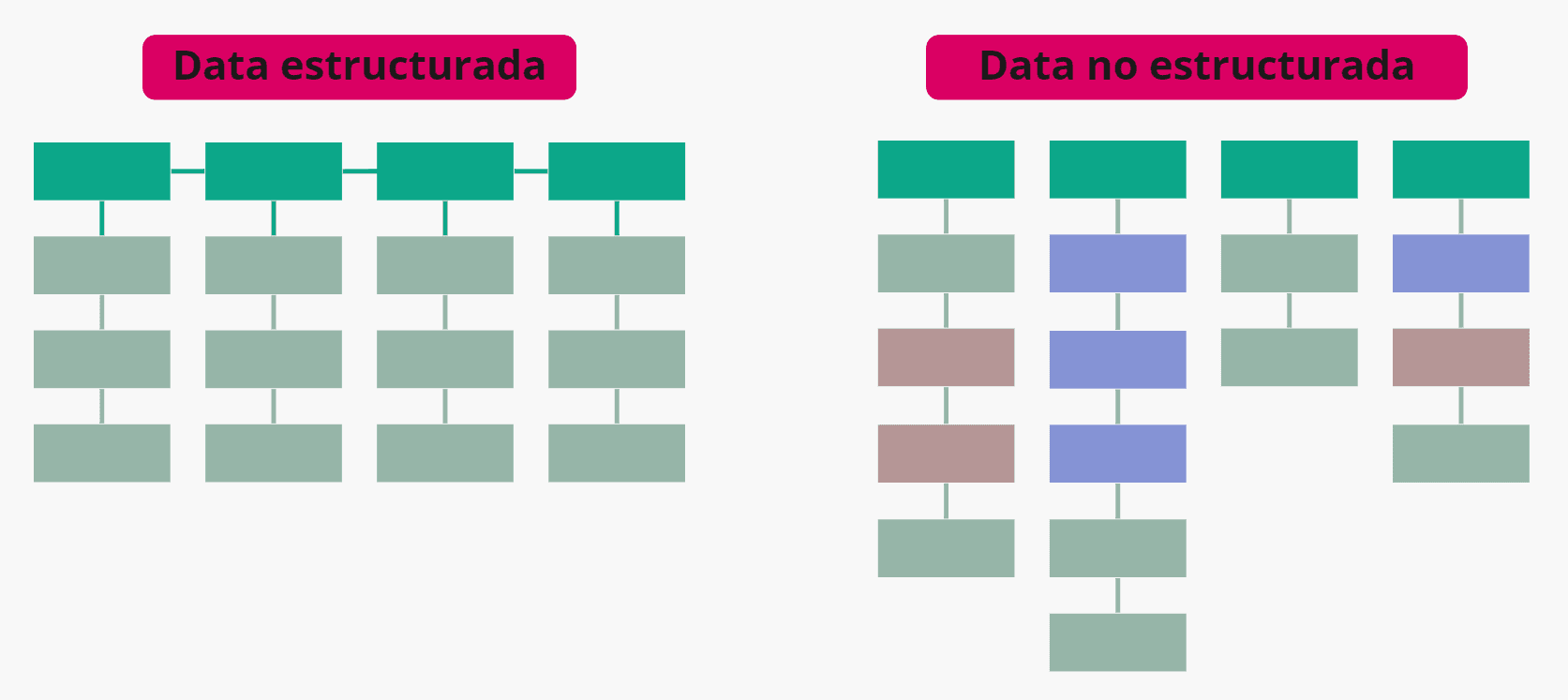
Ambas estructuras se pueden utilizar para obtener resultados y tomar decisiones inteligentes. Sin embargo la data histórica no estructurada es mucho más difícil de analizar. Pero con las herramientas de la nube adecuadas se puede extraer valor de la data desestructurada. Utilizando APIs para crear estructura.
Data histórica: Se trata de la información que las organizaciones van generando con el pasar de los años. La cual generalmente se encuentra desordenada y proveniente de varias fuentes.
APIs: Son herramientas que permiten integrar o comunicar dos sistemas distintos.
Roles
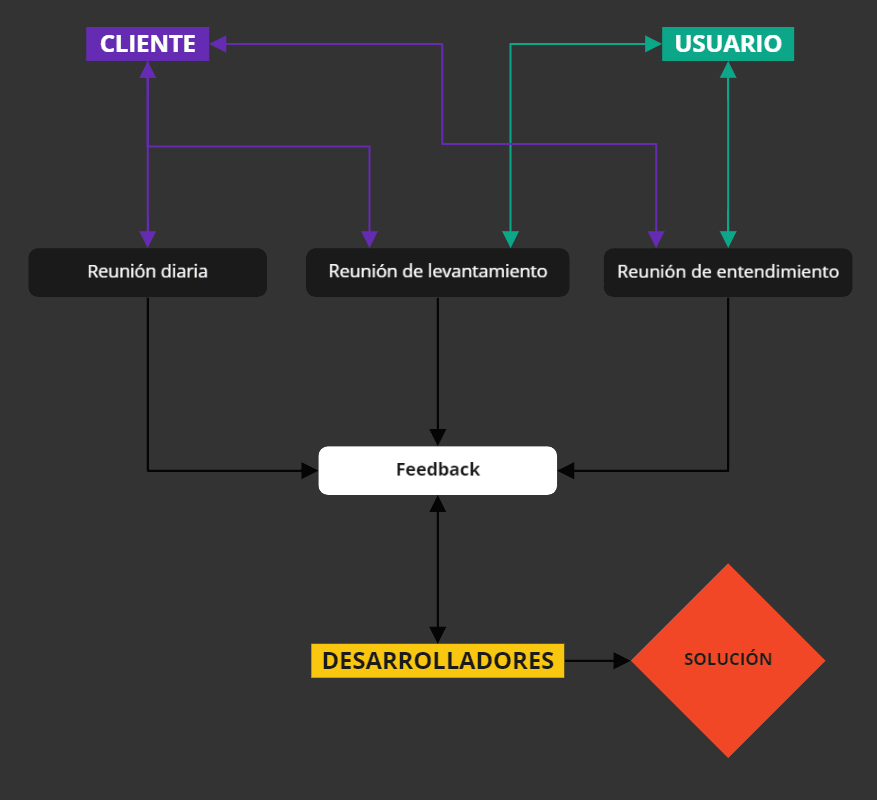
Para llevar adelante un proyecto es necesario que exista una comunicación efectiva entre tres de los roles existentes en un proyecto de datos: El cliente, el usuario y el equipo de desarrollo.
El Cliente
El cliente en este tipo de proyectos cumple un rol fundamental, pues al trabajar con datos de una organización se vuelve imperante que el equipo de desarrollo durante todo el proceso de construcción del proyecto vaya entendiendo como funciona la empresa cliente y en qué manera trabajan su data. En esencia se trata de comprender la lógica de negocio.
Este entendimiento del negocio se genera de la mano entre los desarrolladores y el cliente, el equipo de desarrollo debe velar por resolver todas sus dudas respecto al funcionamiento del negocio y el uso de los datos. Por su parte el cliente debe ser capaz de resolver todas estas dudas las cuales marcarán la diferencia para llegar a obtener un buen resultado.
Reuniones con el cliente
Lo primero que se hace al comenzar el proyecto es iniciar una etapa que consiste en una serie de reuniones con el cliente para entender sus expectativas, y su flujo, de esta forma poder definir la solución que necesita. Las primeras reuniones que se realizan entre cliente y desarrolladores son denominadas “reuniones de levantamiento” y todas aquellas que sean posteriores se denominan “reuniones de entendimiento”. Ambas reuniones tienen como fin llegar al corazón del problema que se busca solucionar e idealmente llegar en conjunto a determinar que valor tienen los datos para el negocio. Sin embargo el verdadero objetivo de estas reuniones es entender la lógica de negocio (de ahí el nombre). Este proceso de entendimiento abarca conocer cómo se obtienen los datos, qué procesos manuales son llevados a cabo con los mismos, cómo son presentados y en última instancia como se espera que sean visualizados o accedidos, en síntesis: el objetivo de las reuniones de entendimiento es realizar una trazabilidad de los datos que configuran la lógica de negocio.
Durante el desarrollo del proyecto se recomienda que el cliente habilite un Product Owner con el fin de asegurar que la comunicación con el cliente sea aún más efectiva y ágil. Al mismo tiempo un Product Owner en el equipo de desarrollo puede garantizar o asegurar al máximo que los esfuerzos realizados por el equipo de desarrollo apunten directamente a lo que el cliente está buscando y reducir así el desarrollo descartado o las inversiones de tiempo en desarrollo que posteriormente sean modificadas o descartadas por que se alejan de las necesidades del cliente.
El Product Owner en los proyectos de agilidad, es aquel miembro del equipo que pertenece a la organización del cliente el cual apoyará a los desarrolladores y al Scrum master a sacar adelante el proyecto alineado con la visión y el requerimiento de su propia organización.
Ingesta automatizada del cliente
Para el correcto desarrollo del proyecto, el cliente debe velar por garantizar que el equipo de desarrollo tenga disponibles los datos suficientes como para ir construyendo la lógica.
La “subida” de estos archivos suele ser almacenada en zonas de ingesta en algún servicio de computo en la nube, como S3 de AWS.
Las zonas de ingesta corresponden a aquellos directorios o espacios dentro de un Data Lake donde se almacenan los datos que formaran parte del proceso de ingesta en el pipeline o flujo de datos. Estos son utilizados por el equipo de desarrollo para ir probando y construyendo el resultado esperado.
Sin embargo, este proceso no se queda limitado solo al proceso de desarrollo, si no que, para que el flujo de datos de la solución opere correctamente deben abastecerse en en estás zonas de ingesta de nuevos datos periódicamente. Generalmente la frecuencia con la que estos datos son subidos esta directamente relacionado con las ocasiones en que se gatilla todo el proceso, esto en caso de trabajar con un proyecto serverless.
Un proyecto serverless es aquel que solo consume recursos y solo se ejecuta cuando es requerido.
El usuario
Al momento de desarrollar la solución se debe construir siempre orientado hacia el usuario. Para un proyecto de datos un usuario puede ser desde la gerencia de un área y sus supervisores hasta un trabajador que lleva tiempo generando reportes y que ya construyó la solución en forma manual. Solución la cual ahora será trasladada a la nube para de esta forma automatizar su trabajo.
Los usuarios son requeridos por el equipo de desarrollo para entender la solución que se busca desarrollar y en caso de que la solución ya exista y se quiera trasladar a un servicio Cloud.
Para poder garantizar que la solución sea coherente con lo que busca el usuario este debe tener una reunión directamente con el equipo de desarrollo. De esta manera el equipo que desarrollará la solución tendrá todo el contexto, de esta forma podrá comprender el modelo de datos y cómo se obtienen las métricas necesarias. Tal como ocurre con las reuniones de entendimiento este es un proceso iterativo y en el cual se deben resolver todos los detalles relacionados con los datos, específicamente, el flujo por el que pasan los mismos.
Equipo de desarrollo
El equipo de desarrollo, conformado por profesionales de diversas disciplinas del área TI. Son los encargados de sacar adelante la solución.
Por poner un ejemplo podemos encontrarnos profesionales que cumplen roles de: Data Engineer, Data Ops, Dev Ops, Cloud Engineer, Data Analyst.
El contexto del proyecto muta a lo largo de todo el desarrollo y el equipo debe estar siempre enterado y enfocado. El feedback tanto de los usuarios como de los clientes permite a los desarrolladores construir un entregable que cumpla con las expectativas de ambos roles. Podemos sintetizar los conceptos vistos en esta última sección mediante la siguiente imagen:
En el próximo artículo de la serie veremos en detalle qué es un flujo ETL y como los datos se extraen y se transforman. Esperamos que el artículo haya sido de ayuda, si tienes alguna duda o tu organización necesita apoyo para resolver proyectos de este tipo no dudes en contactarnos.
¿Listo para iniciar tu camino en la ciencia de datos?
En Kranio, te acompañamos en cada etapa de tus proyectos de Data Science, desde la identificación y almacenamiento de datos hasta la implementación de soluciones analíticas. Nuestro equipo de expertos está preparado para ayudarte a transformar tus datos en decisiones estratégicas. Contáctanos y descubre cómo podemos impulsar la transformación digital de tu empresa.
Entradas anteriores

Agent harness: patrones de diseño para agentes de IA
Descubre qué es un Agent Harness y los patrones que permiten convertir modelos de IA en agentes capaces de ejecutar tareas, verificar resultados y escalar procesos empresariales.

Spec-driven coding con IA: guia practica para equipos
Descubre cómo el Spec-Driven Coding ayuda a los equipos a usar IA para desarrollar software con más control, mejores pruebas y menos deuda técnica.
