
Observabilidad en DevOps: Guía práctica para implementarla
Imagina poder saber exactamente qué está pasando dentro de tu sistema en tiempo real, anticiparse a los problemas antes de que impacten a tus usuarios y reducir significativamente el tiempo que toma resolver cualquier incidente. Esto es posible gracias a la observabilidad, una práctica cada vez más esencial en el mundo del desarrollo de software y las operaciones.
Si lideras un equipo técnico o trabajas en desarrollo y operaciones, probablemente ya estés familiarizado con términos como monitoreo, alertas y métricas. Sin embargo, la observabilidad es más que eso: es una evolución que te permite tener una visión integral y proactiva de tu sistema.
En este tutorial paso a paso, te explicaré claramente qué es la observabilidad, cómo se diferencia del monitoreo tradicional, por qué es fundamental en el contexto de DevOps y cómo puedes comenzar a aplicarla desde cero para tener un equipo competitivo.
🔍 ¿Qué es la Observabilidad y en qué se diferencia del Monitoreo? 📊
La observabilidad es la capacidad de poder analizar cómo se comporta un sistema basándose en los datos generados externamente (como logs, métricas y trazas) sin necesidad de acceder al código de las aplicaciones. Esto les permite a los equipos entender qué está sucediendo, poder detectar anomalías, realizar análisis de las fallas y poder resolverlas de forma eficiente.
La observabilidad permite resolver preguntas clave como: ¿Qué aplicación del sistema está fallando?, ¿Dónde está sucediendo la falla?, ¿Por qué se produjo?, ¿Cuál es el impacto?, ¿Cuáles aplicaciones del sistema están involucradas en la falla?, ¿Cuántos usuarios están siendo afectados por la falla y durante cuánto tiempo?, entre otras
Por otro lado, el monitoreo tradicional está limitado a alertas basadas en métricas predefinidas, lo que hace que solo puedas detectar situaciones que ya esperas o conoces y resolverlas en el momento en que suceden. La observabilidad, en cambio, te permite detectar situaciones anticipadamente antes de que las fallas escalen, reduce el tiempo de detección de errores y por ende la solución de los mismos y ayuda a tomar decisiones basadas en datos reales.
Diferencias clave:
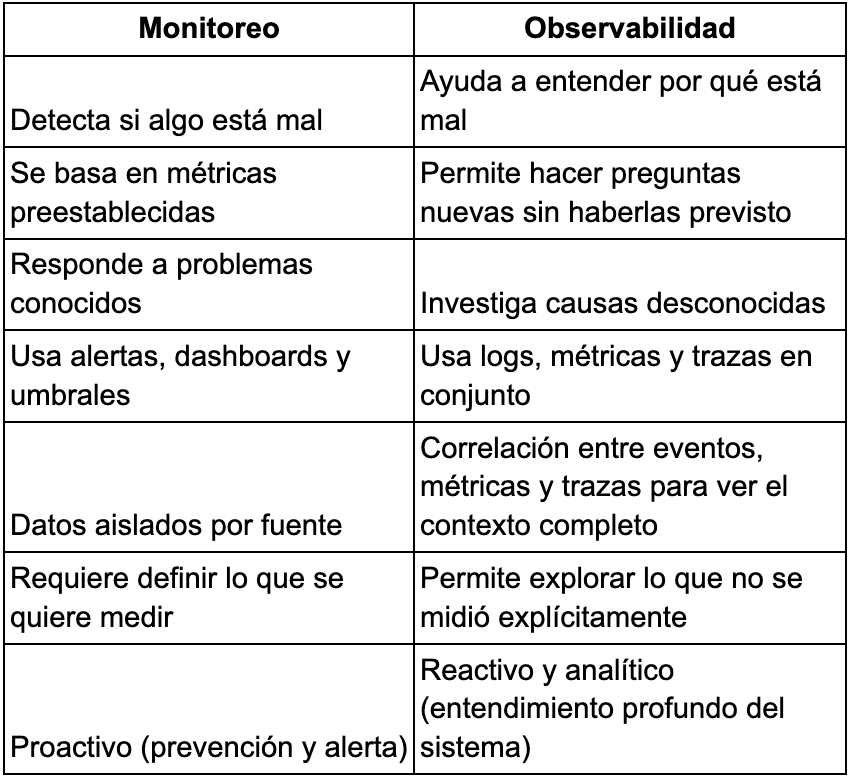
El monitoreo es importante para generar alertas cuando se detectan fallas que superan los umbrales definidos pero si se complementa con observabilidad se puede evitar la repetición de errores a futuro, ayuda a entender las causas raíz de las fallas para solucionarlas y evitar que vuelvan a suceder, juntos permiten reaccionar rápidamente, aprender y crear una mejora continua.
📈 ¿Cómo potencia la Observabilidad al equipo de DevOps?
Al integrar la observabilidad al sistema, no solo se mejora la detección y resolución de problemas, sino que también se fortalece al equipo DevOps, dándole mayor visibilidad, autonomía y capacidad para tomar decisiones basadas en datos reales.
Esto trae consigo ventajas como:
- Se facilita la búsqueda y el diagnóstico de problemas, incluso cuando no han sido previamente definidos.
- Se reduce el tiempo de respuesta ante fallos, ya que se invierte menos tiempo buscando y más tiempo solucionando.
- Se accede a datos en un contexto más amplio por lo que se pueden tomar decisiones más informadas.
- Se mejora el ciclo de aprendizaje continuo, permitiendo prevenir fallas futuras a partir del análisis de incidentes previos.
- Aumenta la colaboración y visibilidad entre equipos (desarrollo, operaciones, QA, entre otros) al tener todos una misma visión del sistema.
⚙️ Ejemplos prácticos de Observabilidad en acción
Para entender mejor cómo una estrategia efectiva de observabilidad puede transformar tu equipo, analicemos dos ejemplos prácticos:
🚨 Escenario 1: Problemas inesperados en producción
Imagina que tu aplicación web comienza a presentar lentitud de forma intermitente. Sin observabilidad, probablemente perderías horas revisando logs, métricas básicas, incluso yendo a revisar el código tratando de encontrar la causa. Con una estrategia de observabilidad, podrías acceder rápidamente a información como trazas distribuidas, métricas específicas y análisis detallados a través de dashboards que te permitan identificar rápidamente que la raíz del problema es una consulta lenta en la base de datos relacionada con un cambio reciente en el código.
🚀 Escenario 2: Lanzamiento exitoso de nuevas funcionalidades
Durante el lanzamiento de una nueva feature, solo con monitoreo, te quedas esperando por un tiempo a ver si suena una alerta y sucede algún error en el sistema y en caso de que suceda empiezas a buscar en varias partes de la aplicación dónde está la falla lo que consume mucho tiempo, al final tal vez terminas deshaciendo el deploy. Con observabilidad puedes monitorear en tiempo real cómo reaccionan los usuarios, cómo se comportan los recursos del servidor y si existen errores en producción y en caso de que existan identificarlos rápidamente para implementar una solución dependiendo del impacto de la falla o incluso poder ver si la falla no sucedió por el nuevo paso a producción sino que tal vez fue una coincidencia por alguna otra aplicación del sistema. Esto facilita detectar temprano cualquier problema, corregirlo rápidamente y asegurar una experiencia positiva desde el primer minuto.
📘 Tutorial paso a paso: Cómo implementar la Observabilidad desde cero
Si estás convencido del valor de la observabilidad y quieres comenzar a implementarla, sigue estos pasos prácticos:
Paso 1️⃣: Define objetivos claros y métricas relevantes
Antes de instalar e implementar herramientas, define claramente qué preguntas necesitas responder frecuentemente:
- ¿Qué partes del sistema consumen más recursos?
- ¿Cuáles funciones tienen peor rendimiento?
- ¿Cómo afectan los cambios recientes al desempeño general?
Paso 2️⃣: Escoge herramientas clave
Hay tres componentes esenciales para una estrategia efectiva de observabilidad:
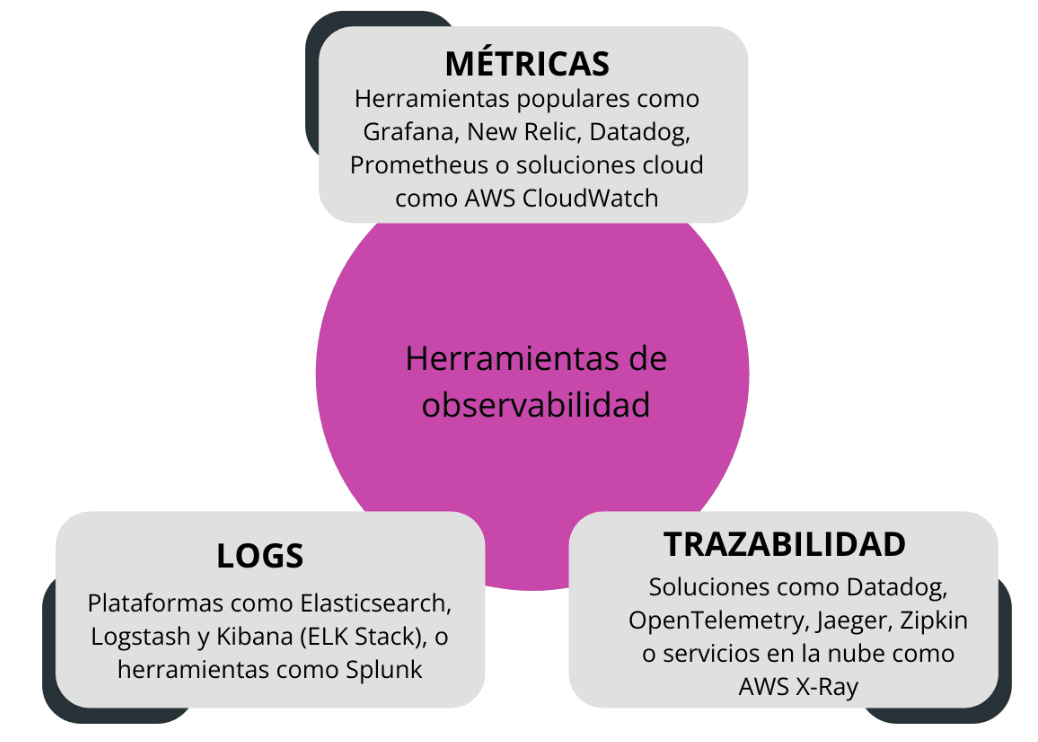
Para empezar son recomendables:
- Prometheus: es open source y es ideal para Kubernetes y microservicios
- Grafana: Sirve para visualizar las métricas en dashboards
- Datadog: Es útil si prefieres una solución SaaS completa sin administrar infraestructura
Paso 3️⃣: Configura la observabilidad en tu aplicación
Esto consiste en preparar tu aplicación para que genere datos útiles sobre su comportamiento interno. Para esto, implementa librerías que permitan recolectar métricas y trazas. Por ejemplo, en Java puedes usar Micrometer para métricas y OpenTelemetry para trazabilidad.
Ejemplo de instrumentación básica en Java con Micrometer:
Paso 4️⃣: Centraliza y visualiza los datos
Una vez que hayas implementado la observabilidad en tu sistema y la hayas creado en las aplicaciones, centraliza los datos utilizando herramientas como Grafana para métricas, Kibana para logs y New Relic para trazas. Esto te permitirá analizar fácilmente la información en tiempo real.
Paso 5️⃣: Establece alertas inteligentes
Define alertas que no solo te avisen de problemas conocidos, sino también situaciones anómalas. Ejemplos útiles pueden incluir:
- Incremento repentino en la latencia promedio.
- Consumo excesivo e inesperado de memoria o CPU.
- Incremento en tasas de error de endpoints específicos.
- Picos de tráfico inesperados
- Inactividad o detención de algún proceso
Paso 6️⃣: Capacita a tu equipo
Por último, dedica tiempo a capacitar a tu equipo en las herramientas y prácticas implementadas. La observabilidad es poderosa, pero el verdadero valor está en que todos puedan usarla eficazmente.
Mejores prácticas para mantener una estrategia efectiva
📌Mantenlo simple al inicio: Comienza pequeño y escala paulatinamente.
📌Automatiza todo lo posible: Automatiza procesos de configuración, instrumentación y alertas.
📌Revisa regularmente tus métricas y dashboards: Asegúrate de que sigan siendo relevantes y útiles.
📌Fomenta una cultura proactiva: Usa la información obtenida para prevenir y no solo reaccionar.
📌Realiza sesiones colaborativas de aprendizaje continuo con reuniones periódicas donde el equipo pueda compartir las fallas y aprender cómo se solucionaron o contribuir con soluciones para fallas frecuentes.
📌Crea tableros con correlaciones , esto te permite visualizar múltiples señales (métricas, logs, trazas) en un solo lugar para entender cómo interactúan entre sí.
Conclusión: De operación tradicional a equipo experto en DevOps
Implementar una estrategia de observabilidad efectiva transforma radicalmente la forma en que tu equipo enfrenta los desafíos operativos, pasando de reaccionar ante los problemas a anticiparlos y resolverlos rápidamente. La observabilidad no es solo una herramienta técnica, sino una cultura que potencializa a tu equipo para entregar software más robusto, eficiente y confiable.
¡Es hora de que tu equipo DevOps se consolide como una pieza clave en la evolución tecnológica de tu organización!
¿Quieres que tu equipo DevOps deje de apagar incendios y comience a prevenirlos?👉 Contáctanos y te ayudaremos a construir una estrategia de observabilidad efectiva adaptada a tu sistema.
Entradas anteriores
¿RabbitMQ (el rey de las colas) o Apache Kafka (el gigante de los eventos)?
Conoce las diferencias entre RabbitMQ y Apache Kafka, sus casos de uso y las novedades de 2026 para elegir la mejor solución de mensajería para tu arquitectura.

Cómo implementar un proxy para bases de datos con PgBouncer: guía paso a paso
Aprende a implementar un proxy para bases de datos con PgBouncer. Mejora el rendimiento, reduce conexiones y escala PostgreSQL fácilmente.
