
Cómo Orquestar Flujos de Datos en una Nube Híbrida con AWS Step Functions
Este artículo está basado en el webinar “Automatiza flujos de Datos entre Legados y Cloud”. El articulo es más detallado y paso a paso con código. Si prefieres ver el webinar de 1 ahora, dale click acá y elige 'ver replay' al final.
¿Por qué orquestar procesos?
Orquestar y automatizar procesos es parte de los objetivos de las empresas en su fase de transformación digital. Esto porque muchas compañías con más años en el mercado, tienen sistemas legados cumpliendo roles esenciales hace décadas. Por lo mismo, cuando las empresas buscan modernizar sus procesos, lo correcto es hacerlo de manera incremental, con servicios desacoplados y desplegados en una nube híbrida: con componentes cloud y on premise trabajando en conjunto.
Uno de los servicios de Amazon Web Services que más nos gustan en Kranio y en el que somos expertos, es Step Functions. Consiste en una máquina de estados, muy similar a un diagrama de flujo con inputs y outputs secuenciales donde cada salida depende de cada entrada.
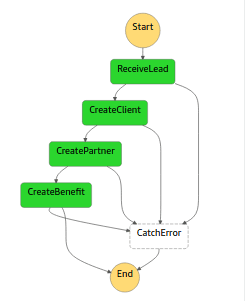
Cada paso es una función Lambda, es decir, código serverless que sólo se ejecuta cuando se necesita. AWS provee el runtime y nosotros no tenemos que administrar ningún tipo de servidor.
Caso de uso
Un caso que nos ayuda a entender cómo aplicar Step Functions, es el de crear registros secuenciales en múltiples tablas de una DB on premise desde una aplicación en la nube, a través de una api rest con una arquitectura basada en eventos.
Este caso se puede resumir en un diagrama como este:
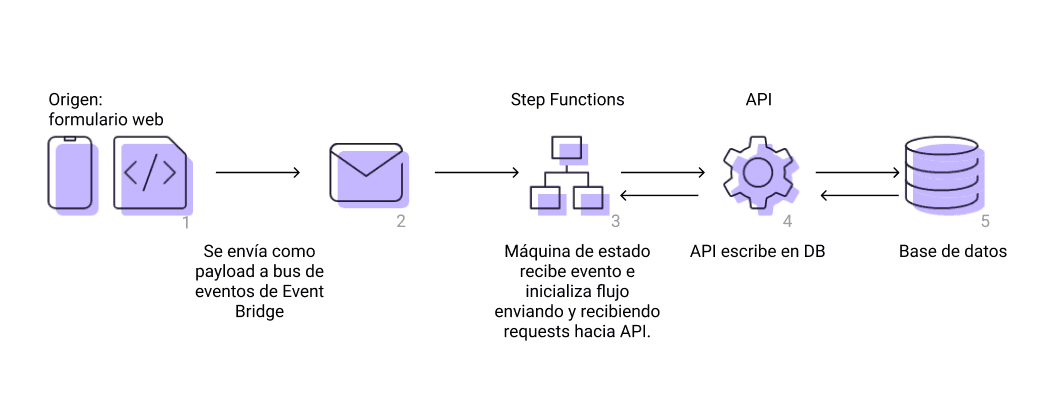
Aquí podemos ver:
- Un origen de los datos, como por ejemplo, un formulario web.
- Payload de datos: son los datos que necesitamos para registrarlos en la DB.
- Eventos de CloudWatch: También llamados Event Bridge, son eventos que permiten “triggerear” servicios de AWS, en este caso, el State Machine.
- Api Gateway: Es el servicio de AWS que permite crear, publicar, mantener y monitorear apis rest, http o websockets.
- Una base de datos relacional.
Ventajas
Las ventajas de orquestar on premise desde la nube son:
- Reutilización de componentes que ya existen sin dejarlos de lado
- La solución es desacoplada, por lo que cada acción que se debe realizar, tiene su propio desarrollo, facilitando su mantención, identificación de errores, etc.,
- Si los requerimientos del negocio cambian, sabemos qué pasó y qué se debe modificar o entre qué pasos se debe añadir un nuevo estado.
- en caso de requerir cambios, se mitiga el impacto que puede haber en los on premise ya que la orquestación está en la nube, .
- Al haber alternativas serverless, no es necesario administrar servidores ni sus sistemas operativos.
- Son soluciones de bajo costo. Si quieres conocer más revisa los precios del uso de Lambda, Api Gateway, SNS y Eventos CloudWatch.
Y ahora qué?
Ya conoces la teoría sobre orquestar un flujo de datos. Ahora te mostraremos las consideraciones y pasos que debes tener en cuenta para llevarlo a la práctica.
Desarrollo
Los recursos a utilizar son:
- Una cuenta en Amazon Web Services y tener configurado AWS CLI como en este link
- Python +3.7
- El framework Serverless (conoce aquí cómo hacer el setup)
- La librería Boto3 de Python
Cómo partir
Al ser una orquestación necesitaremos identificar los pasos secuenciales que queremos orquestar. Y como la orquestación es para automatizar, el flujo también debe iniciar automáticamente.
Para esto nos basaremos en el caso de uso presentado más arriba, y supondremos que la DB en la que escribimos, corresponde a uno de los componentes del CRM de una empresa, es decir, una de las tecnologías con las que se gestiona a la base de clientes.
Crearemos una solución basada en eventos, iniciando el flujo con la recepción de un mensaje originado por alguna fuente (como por ejemplo, un formulario web).
Luego de que el evento es recibido, su contenido (payload) debe enviarse vía POST a un endpoint para que ingrese a la base de datos. Esta DB puede ser cloud u on premise y el endpoint debe tener un backend que pueda realizar operaciones limitadas en la DB.
Para facilitar el despliegue de lo que se debe desarrollar se utiliza el framework Serverless que nos permite desarrollar y desplegar.
El proyecto se dividirá en 3 partes:
| Nombre | Descripción |
|---|---|
| Api Gateway | Una api en Api Gateway que se encargará de crear los registros en la DB |
| Infraestructura | Aquí simularemos una DB on premise y crearemos un Event Bus de Event Bridge para inicializar el flujo |
| Orquestación | El código de los Step Functions |
Luego estos proyectos se despliegan en el orden infraestructura >> step-functions >> api-gateway.
Puede ser un mismo directorio, donde dedicamos 3 carpetas. La estructura sería como la siguiente:
├──api-gateway
│ ├── scripts-database
│ │ ├── db.py
│ │ └── script.py
│ ├── libs
│ │ └── api_responses.py
│ ├── serverless.yml
│ └── service
│ ├── create_benefit_back.py
│ ├── create_client_back.py
│ └──create_partner_back.py
├──infraestructura
│ └── serverless.yml
└── step-functions
├── functions
│ ├── catch_errors.py
│ ├── create_benefit.py
│ ├── create_client.py
│ ├── create_partner.py
│ └── receive_lead.py
├── serverless.yml
└── services
└──crm_service.py
Talk is cheap. Show me the code.
Y con esta frase célebre de Linus Torvalds, veremos el código esencial del proyecto que estamos creando. El detalle puedes verlo aquí.
Backend
Los endpoint previos no nos sirven de nada si no tienen un backend. Para relacionar cada endpoint con un backend, se debe crear funciones Lambda que escriban en la base de datos los parámetros que el endpoint recibe. Una vez creadas las funciones Lambda, ingresamos su ARN en el parámetro “uri” dentro de “x-amazon-apigateway-integration“.
Algo clave de las funciones Lambda es que se componen de un método principal llamado handler que recibe 2 parámetros: message y context. Message es el payload de entrada, y Context contiene datos sobre la invocación de la función y datos de la ejecución en sí. Todas las funciones Lambda deben recibir un input y generar un output. Puedes conocer más aquí.
Las funciones de cada endpoint son muy similares y sólo varían en los datos que la función necesita para poder escribir en la tabla que le corresponda.
Función: createClient
Rol: crea registro en la tabla CLIENTS de nuestra DB
def handler(message, context):
try:
msg = json.loads(message["body"])
data = return_tuple(
msg["name"],
msg["lastname"],
msg["rut"],
msg["mail"],
msg["phone"]
)
conn = connect()
res = create_record(conn, INSERT_CLIENT, data)
return response_success(res["success"], res["message"])
except Exception as e:
print("Exception: ", e)Función: createPartner
Rol: crea registro en la tabla PARTNER de nuestra DB
def handler(message, context):
try:
crm_service = CRMService(message)
crm_service.create_partner()
return message
except Exception as e:
print(e)
return eFunción: createBenefit
Rol: crea registro en la tabla BENEFIT de nuestra DB
def handler(message, context):
try:
crm_service = CRMService(message)
r = crm_service.create_benefit()
return r
except Exception as e:
print(e)
return eIaaC - Infraestructura como Código
En el código de serverless.yml declaramos todos los recursos que estamos definiendo. Para su despliegue, se debe tener correctamente configurado AWS CLI y luego ejecutar el comando
$ sls deploy -s {stage} -r {mi región de AWS}Esto genera un stack de Cloudformation que agrupa todos los recursos que declaraste. Conoce más aquí.
En los archivos Serverless.yml verás unos valores como estos:
${file(${self:provider.stage}.yml):db_pass}
Éstos corresponden a referencias hacia strings en otros documentos yml dentro de la misma ruta, y que apuntan hacia un valor en especial. Puedes conocer más sobre esta forma de trabajar aquí.
Api Gateway
Para la api rest levantaremos un Api Gateway con un proyecto Serverless.
El objetivo de la API es recibir los requests de parte de los Step Functions, registrando datos en la base de datos.
El Api Gateway nos permitirá exponer endpoints a los que realizar métodos. En este proyecto sólo crearemos métodos POST.
Te mostraremos lo esencial del proyecto y puedes ver el detalle aquí.
OpenAPI Specification
Una alternativa para declarar la API, sus recursos y métodos,es hacerlo con OpenAPI. Para conocer más sobre Open Api, lee este artículo que hicimos sobre él.
Este archivo es leído por el servicio Api Gateway y genera la API.
Importante: si queremos crear un Api Gateway es necesario añadir al OpenApi una extensión con información que sólo AWS puede interpretar. Por ejemplo: el endpoint create_client que llamamos vía POST, recibe un request body que un backend en específico debe procesar. Ese backend es un lambda. La relación entre el endpoint y la función lambda se declara en esta extensión. Puedes conocer más sobre esto aquí.
openapi: "3.0.1"
info:
title: "testapi"
version: "2021-01-21T15:44:04Z"
servers:
- url: "https://{id-de-api}.execute-api.{TU-REGION-AQUI}.amazonaws.com/{basePath}"
variables:
basePath:
default: "/dev"
paths:
/create_client:
post:
responses:
200:
description: "200 response"
content:
application/json:
schema:
$ref: "#/components/schemas/ApiResponseBody"
requestBody:
description: req body para crear cliente
content:
application/json:
schema:
$ref: "#/components/schemas/CreateClientRequestBody"
example:
name: alice
lastname: cooper
rut: 11111111-1
phone: 54545454
mail: acooper@alice.com
security:
- api_key: []
x-amazon-apigateway-integration:
uri: arn:aws:apigateway:{TU-REGION-AQUI}:lambda:path/2015-03-31/functions/arn:aws:lambda:{TU-REGION-AQUI}:{TU-ACCOUNT-ID-AQUI}:function:${stageVariables.CreateClientBackLambdaFunction}/invocations
responses:
default:
statusCode: 200
credentials: arn:aws:iam::{TU-ACCOUNT-ID-AQUI}:role/${stageVariables.ApiGatewayStepFunctionLambdaRole}
httpMethod: POST
passthroughBehavior: "when_no_match"
type: aws_proxy
/create_partner:
post:
responses:
200:
description: "200 response"
content:
application/json:
schema:
$ref: "#/components/schemas/ApiResponseBody"
requestBody:
description: req body para crear socio
content:
application/json:
schema:
$ref: "#/components/schemas/CreatePartnerRequestBody"
example:
rut: 11111111-1
store: ESTACION_CENTRAL
security:
- api_key: []
x-amazon-apigateway-integration:
uri: arn:aws:apigateway:{TU-REGION-AQUI}:lambda:path/2015-03-31/functions/arn:aws:lambda:{TU-REGION-AQUI}:{TU-ACCOUNT-ID-AQUI}:function:${stageVariables.CreatePartnerBackLambdaFunction}/invocations
responses:
default:
statusCode: 200
credentials: arn:aws:iam::{TU-ACCOUNT-ID-AQUI}:role/${stageVariables.ApiGatewayStepFunctionLambdaRole}
httpMethod: POST
passthroughBehavior: "when_no_match"
type: aws_proxy
/create_benefit:
post:
responses:
200:
description: "200 response"
content:
application/json:
schema:
$ref: "#/components/schemas/ApiResponseBody"
requestBody:
description: req body para crear beneficio
content:
application/json:
schema:
$ref: "#/components/schemas/CreateBenefitRequestBody"
example:
rut: 11111111-1
wantsBenefit: true
security:
- api_key: []
x-amazon-apigateway-integration:
uri: arn:aws:apigateway:{TU-REGION-AQUI}:lambda:path/2015-03-31/functions/arn:aws:lambda:{TU-REGION-AQUI}:{TU-ACCOUNT-ID-AQUI}:function:${stageVariables.CreateBenefitBackLambdaFunction}/invocations
responses:
default:
statusCode: 200
credentials: arn:aws:iam::{TU-ACCOUNT-ID-AQUI}:role/${stageVariables.ApiGatewayStepFunctionLambdaRole}
httpMethod: POST
passthroughBehavior: "when_no_match"
type: aws_proxy
components:
schemas:
CreateClientRequestBody:
title: Create Client Req Body
type: object
properties:
name:
type: string
lastname:
type: string
rut:
type: string
phone:
type: string
mail:
type: string
CreatePartnerRequestBody:
title: Create Partner Req Body
type: object
properties:
rut:
type: string
store:
type: string
CreateBenefitRequestBody:
title: Create Benefit Req Body
type: object
properties:
rut:
type: string
wantsBenefit:
type: bool
ApiResponseBody:
title: Api Res Body
type: object
properties:
statusCode:
type: integer
message:
type: string
description:
type: stringAl momento de desplegar el proyecto, Api Gateway interpretará este archivo y creará esto en tu consola AWS:
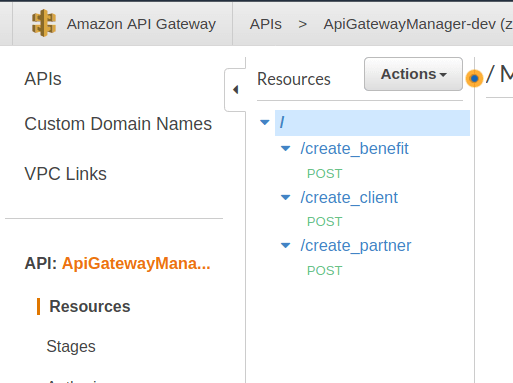
Para conocer la URL de la API desplegada, debes ir al menú Stages. El stage es un estado de tu api en un momento determinado (dato: puedes tener todos los stage que quieras con distintas versiones de tu API). Aquí puedes indicar una abreviación para el ambiente en el que estás trabajando (dev, qa, prd), puedes indicar la versión de la api que estás haciendo (v1, v2) o indicar que corresponde una versión de prueba (test).
En la consola de Api Gateway, indicamos que realizaríamos un deploy con nombre de stage “dev”, por lo tanto, al ir a Stage verás algo así:
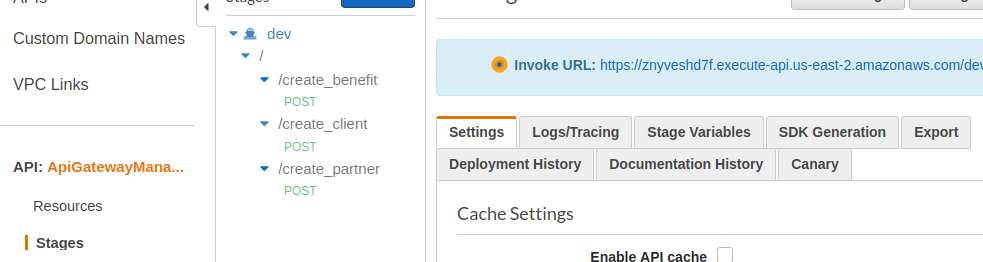
Las URL de cada endpoint las puedes conocer haciendo click en los nombres listado. Así se ve el endpoint de create_client:
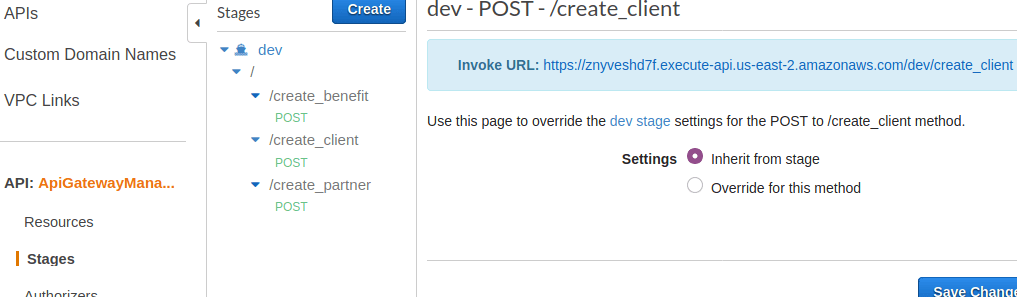
Infraestructura
Aquí crearemos la base de datos relacional y el bus de eventos de Event Bridge.
Por ahora la DB estará en la nube de AWS, pero podría tratarse de una base de datos en tu propio data center o en otra nube.
El bus de eventos de Event Bridge nos permite comunicar 2 componentes aislados que incluso pueden estar en arquitecturas distintas. Conoce más sobre este servicio aquí
Este repositorio es más pequeño que el anterior, ya que sólo declara 2 recursos.
Serverless.yml
# serverless.yml
service: webinar-iass
provider:
name: aws
runtime: nodejs12.x
stage: ${opt:stage, 'dev'}
region: {TU-REGION-AQUI}
versionFunctions: false
deploymentBucket:
# aquí debe ir el nombre de un bucket de S3 que determines para deployment. Ejemplo: mi_proyecto_serverless_s3
# si pones el mismo en cada archivo serverless, tu deploy por proyecto quedará ordenado y dentro del mismo bucket.
name: kranio-webinar
resources:
- Resources:
WebinarMariaDB:
Type: AWS::RDS::DBInstance
Properties:
DBName: WebinarMariaDB
AllocatedStorage: '5'
Engine: MariaDB
DBInstanceClass: db.t2.micro
# aquí va el usuario y pass de base de datos. self:provider.stage hace que se tome el parámetro de ambiente del deploy
# y que se abra el archivo que tenga ese nombre (ej. dev.yml). así puedes parametrizar tus valores.
MasterUsername: ${file(${self:provider.stage}.yml):db_user}
MasterUserPassword: ${file(${self:provider.stage}.yml):db_pass}
DeletionPolicy: Snapshot
# aquí declaramos el event bus de Event Bridge. Para escribir aquí.
WebinarEventBus:
Type: AWS::Events::EventBus
Properties:
Name: WebinarEventBus
Es necesario que crees las siguientes tablas en tu DB. Puedes guiarte por estos scripts para la base de datos que hay aq
| CLIENTS | |
|---|---|
| name | VARCHAR(25) |
| lastname | VARCHAR(25) |
| rut | VARCHAR(25) |
| VARCHAR(25) | |
| phone | VARCHAR(25) |
| PARTNERS | |
|---|---|
| rut | VARCHAR(25) |
| store | VARCHAR(25) |
| BENEFIT | |
|---|---|
| rut | VARCHAR(25) |
| wantsBenefit | BOOL |
Con estos pasos damos por finalizada la creación de la infraestructura.
Step Functions
Cada “paso” del State Machine que crearemos, es una función Lambda. A diferencia de los Lambda de los que hablé en el ítem de Api Gateway y que tienen el rol de escribir en la DB, éstos realizan requests a los endpoint del Api Gateway.
Según la arquitectura indicada más arriba basada en un flujo secuencial, el State Machine debiera tener estos pasos:
- Recibir datos de un origen (ej. Formulario web) a través del evento de Event Bridge.
- Tomar los datos del evento, armar un payload con el nombre, apellido, teléfono, sucursal y rut al endpoint create_client para que el backend lo escriba en la tabla CLIENTS
- Tomar los datos del evento, armar un payload con el rut y sucursal al endpoint create_partner para que el backend lo escriba en la tabla PARTNERS
- Tomar los datos del evento, armar un payload con el rut y wantsBenefit al endpoint create_benefit para que el backend lo escriba en la tabla BENEFITS
- Se puede crear un Lambda adicional al que llega el flujo en caso de haber un error en la ejecución (ejemplo: que el endpoint esté abajo). En el caso de este proyecto, se llama catch_errors.
Por lo tanto, se hace un Lambda por acción de cada paso.
Función: receive_lead
Rol: recibe el evento de Event Bridge. Lo limpia y se lo pasa al siguiente Step. Este paso es importante porque cuando se recibe un evento, éste llega en un documento JSON con atributos definidos por Amazon, y el contenido del evento (el JSON del formulario) viene anidado dentro de un atributo llamado “detail”.
Cuando un origen te envía un evento a través de Event Bridge, el payload luce así:
{
"version": "0",
"id": "c66caab7-10f8-d6e9-fc4e-2b92021ce7ed",
"detail-type": "string",
"source": "kranio.event.crm",
"account": "{tu número de cuenta}",
"time": "2021-01-26T21:52:58Z",
"region": "{tu región}",
"resources": [],
"detail": {
"name": "Camila",
"lastname": "Saavedra",
"rut": "9891283-0",
"phone": 56983747263,
"mail": "csaavedra@micorreo.com",
"store": "est_central",
"wantsBenefit": false,
"origin": "app"
}
}Podemos definir un Lambda que retorne el contenido de “detail” a la función siguiente, como en el siguiente ejemplo:
def handler(message, context):
print('Recibiendo evento...')
return message["detail"]Función: create_client
Rol: Recibe en message el contenido del Lambda del paso anterior. Toma el contenido y lo pasa como argumento a la instancia de la clase CRMService.
def handler(message, context):
try:
crm_service = CRMService(message)
crm_service.create_client()
return message
except Exception as e:
print ("Exception: ", e)
return e
En la clase CRMService declaramos los métodos que realizará los request según endpoint. En este ejemplo, el request es hacia el endpoint create_client. Para las llamadas hacia la API se utilizó la librería Requests de Python:
class CRMService:
def __init__(self, payload):
self.payload = payload
def create_client(self):
try:
r = requests.post(url=URL+CREATE_CLIENT, data=json.dumps(self.payload))
# si el código de respuesta es distinto de 200 puedes retornar una excepción.
if r.status_code != 200:
return Exception (r.text)
return json.loads(r.text)
except Exception as e:
return eLas funciones Lambda para create_partner y create_benefit son similares a create_client, con al diferencia de que llaman a los endpoint que corresponde. Puedes revisar caso a caso en esta parte del repositorio.
Función: catch_error.py
Rol: toma los errores que se presentan y los puede retornar para diagnosticar qué puede haber pasado. Es una función Lambda como cualquier otra, por lo que también tiene un handler, context y retorna un json.
def handler(message, context):
exception_message = {
"success":False,
"description": "ha ocurrido una excepcion en el proceso. revisar log",
"message": message
}
return exception_messageLuego declaramos el Serverless.yml de este proyecto
service: webinar-step-functions
# frameworkVersion: '2.3.0'
provider:
name: aws
runtime: python3.7
stage: ${opt:stage, 'dev'}
region: {TU-REGION-AQUI}
prefix: ${self:service}-${self:provider.stage}
versionFunctions: false
deploymentBucket:
# aquí debe ir el nombre de un bucket de S3 que determines para deployment. Ejemplo: mi_proyecto_serverless_s3
# si pones el mismo en cada archivo serverless, tu deploy por proyecto quedará ordenado y dentro del mismo bucket.
name: kranio-webinar
package:
excludeDevDependencies: false
custom:
prefix: '${self:service}-${self:provider.stage}'
# arn_prefix es un string que se repetiría muchas veces si no se parametriza. en dev.yml podrás ver qué contiene.
# según tus variables por ambiente, debes hacer un documento en caso de ser necesario.
arn_prefix: '${file(${self:provider.stage}.yml):arn_prefix}'
defaultErrorHandler:
ErrorEquals: ["States.ALL"]
Next: CatchError
# declaración de todas las funciones lambda
functions:
receiveLead:
handler: functions/receive_lead.handler
createClient:
handler: functions/create_client.handler
createPartner:
handler: functions/create_partner.handler
createBenefit:
handler: functions/create_benefit.handler
catchErrors:
handler: functions/catch_errors.handler
# los step functions
stepFunctions:
stateMachines:
CreateClientCRM:
# aqui indicamos que el state machine se inicia cuando
# ocurre el evento eventBridge que tiene ese eventBusName y
# source en específico
name: CreateClientCRM
events:
- eventBridge:
eventBusName: WebinarEventBus
event:
source:
- "kranio.event.crm"
definition:
# aqui indicamos que el state machine parte con este paso.
Comment: inicia proceso de inscripcion de cliente
StartAt: ReceiveLead
States:
# ahora indicamos los stados.
# type indica que estos pasos son tareas.
# resource indica el arn de la función lambda que
# se debe ejcutar en este paso
# next indica el paso que viene
# catch indica a qué función llamamos si ocurre un error, en este caso, catch_error.
ReceiveLead:
Type: Task
Resource: '${self:custom.arn_prefix}-receiveLead'
Next: CreateClient
Catch:
- ${self:custom.defaultErrorHandler}
CreateClient:
Type: Task
Resource: '${self:custom.arn_prefix}-createClient'
Next: CreatePartner
Catch:
- ${self:custom.defaultErrorHandler}
CreatePartner:
Type: Task
Resource: '${self:custom.arn_prefix}-createPartner'
Next: CreateBenefit
Catch:
- ${self:custom.defaultErrorHandler}
CreateBenefit:
Type: Task
Resource: '${self:custom.arn_prefix}-createBenefit'
Catch:
- ${self:custom.defaultErrorHandler}
End: true
CatchError:
Type: Task
Resource: '${self:custom.arn_prefix}-catchErrors'
End: trueAhora ya tenemos las funciones Lambda de cada paso del State Machine, tenemos la API que escribe en la DB y tenemos el endpoint expuesto para poder realizar requests.
Enviando un mensaje al bus de eventos de Event Bridge
Para que todo esto comience a interactuar, es necesario enviar el evento que inicialice el flujo.
Suponiendo que estamos trabajando en el CRM de tu empresa, y que los datos iniciales los estás obteniendo de un formulario web, la manera de escribir en el bus de eventos que inicializará el flujo es a través del SDK de AWS. Conoce los lenguajes para los que está disponible aquí
Si estás trabajando con Python, la manera de enviar el formulario sería esta:
client = boto3.client('events')
# ejecutar este script permite enviar un evento de eventbridge
# Source y EventBusName deben coincidir con lo que declaras en serverless.yml
response = client.put_events(
Entries=[
{
'Time': datetime.now(),
# el source del evento
'Source': 'kranio.event.crm',
'Resources': [
'string',
],
'DetailType': 'Inscripcion para CRM ',
# payload son los datos del formulario.
'Detail': json.dumps(payload),
'EventBusName': 'WebinarEventBus'
},
]
)Al haber configurado todo correctamente, debes ir hacia el servicio Step Functions de tu consola AWS y ver el listado de los eventos enviados:
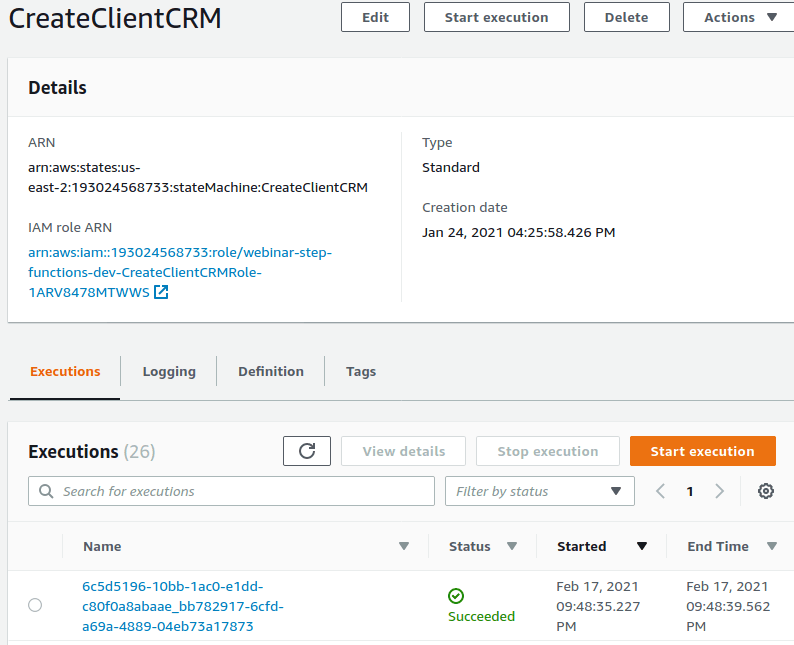
Si eliges el último evento, verás la secuencia de ejecución de los Step Functions y el detalle de sus inputs y outputs.:
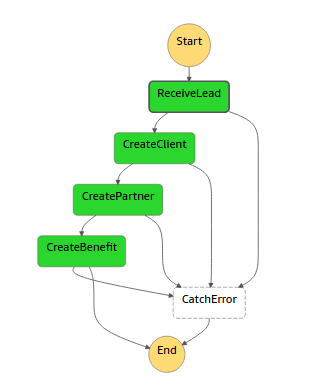
Donde al elegir el paso ReceiveLead, el input corresponde al payload enviado como evento vía Event Bridge.
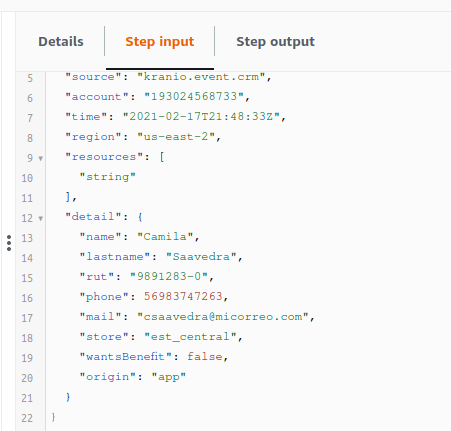
La prueba de la verdad
Si ingresas a tu base de datos (ya sea con el cliente de la terminal o con un cliente visual intuitivo) verás que cada dato está en cada una de las tablas correspondientes.
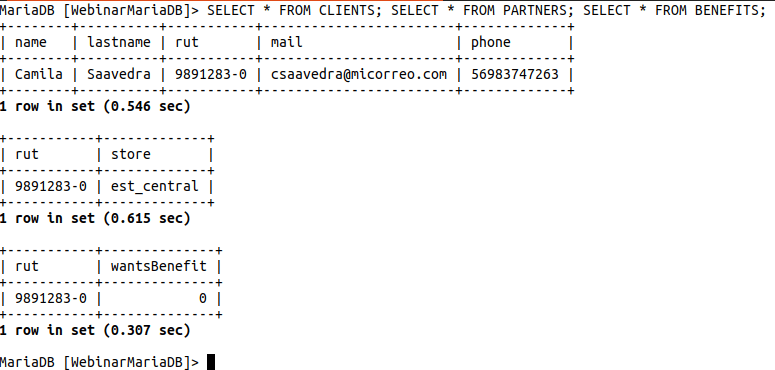
Conclusiones
Step Functions es un servicio muy poderoso si lo que necesitas es automatizar un flujo de acciones secuencial. Ahora elaboramos un ejemplo simple, pero es altamente escalable. Además, trabajar con Step Functions es una invitación a desacoplar los requerimientos de la solución que necesitas implementar, lo que facilita identificar los puntos de fallas.
Este tipo de orquestaciones es totalmente serverless, por lo tanto, es mucho más económico que desarrollar una aplicación que corre en un servidor sólo para cumplir este rol.
Es una excelente forma de experimentar con una nube híbrida, reutilizando e integrando aplicativos de tu data center, e interactuando con servicios cloud.
¿Listo para optimizar tus flujos de datos en entornos híbridos?
En Kranio, contamos con expertos en integración de sistemas y soluciones serverless que te ayudarán a orquestar procesos eficientes entre tus sistemas on-premise y la nube. Contáctanos y descubre cómo podemos impulsar la transformación digital de tu empresa.
Entradas anteriores
Prompt Injection en IA: cómo asegurar tu infraestructura
Descubre qué es el Prompt Injection en IA, cómo funcionan los ataques más recientes y qué estrategias implementar para proteger agentes, copilotos y sistemas basados en LLMs.
¿RabbitMQ (el rey de las colas) o Apache Kafka (el gigante de los eventos)?
Conoce las diferencias entre RabbitMQ y Apache Kafka, sus casos de uso y las novedades de 2026 para elegir la mejor solución de mensajería para tu arquitectura.
