
Agent Harness: Design Patterns for AI Agents

There is a pattern that keeps showing up in teams already using AI every day: the demo is spectacular, but day-to-day operations do not scale. Someone asks a chat for something, copies the response, pastes it into another system, finds an error, goes back to the chat, re-explains all the context... and so on. The model is powerful, but the process remains manual.
The difference between that experience and an agent that completes tasks end-to-end is almost never the model itself. It is everything around it: the agent harness.
In this article, we will explore what an agent harness is, which design patterns every harness should have—without committing to any specific framework—and why it represents a real leap in value compared to using AI through chat interfaces.
What is an Agent Harness?
An agent harness is the software layer that surrounds a language model and turns it into an agent: it provides tools to interact with the world, manages context, executes decisions, verifies results, and applies safety controls.
A simple analogy: the model is the engine; the harness is the rest of the car. Chassis, steering, brakes, dashboard. An engine on a test bench may be impressive, but nobody reaches a destination by driving an engine. That is why two products built on top of the same model can behave radically differently: the difference lies in the harness.
The Agentic Loop
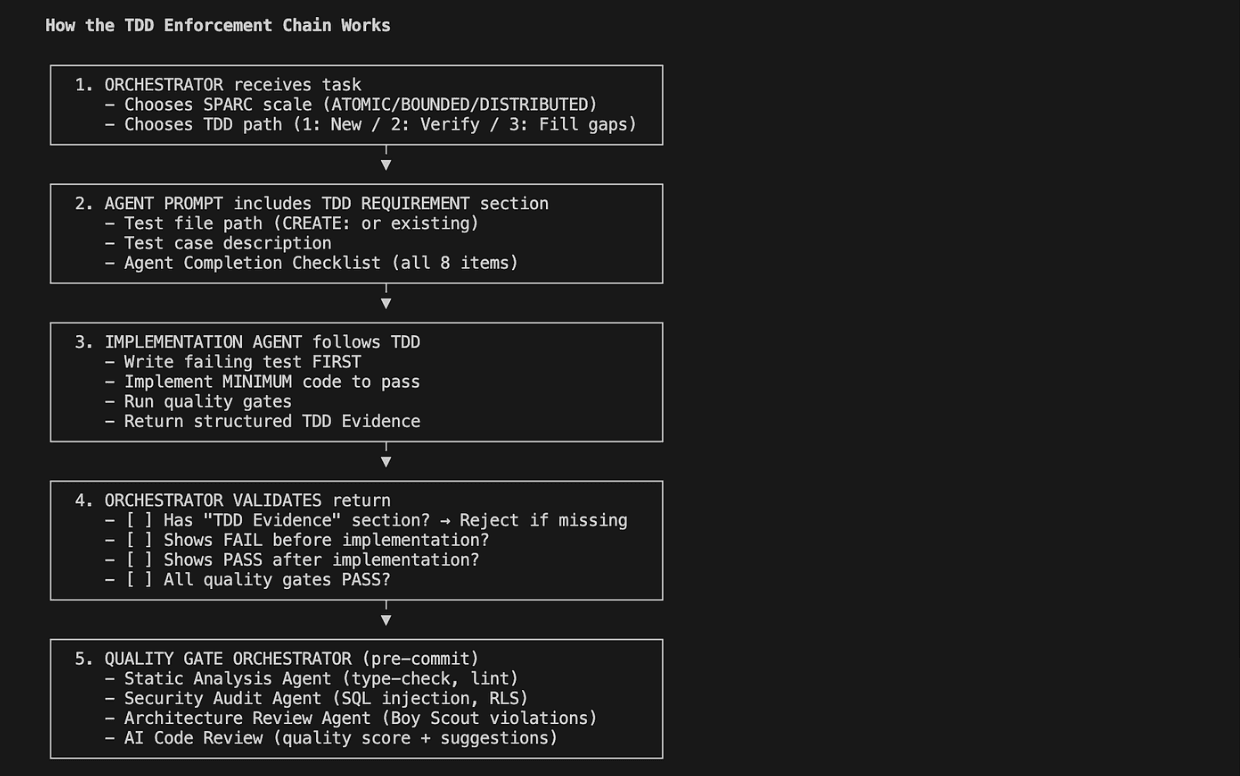
At the heart of every harness is a simple cycle: gather context, decide the next action, execute it with a tool, observe the result, and repeat until the goal is achieved. Conceptually:
while not goal_completed and remaining_budget > 0:
context = prepare_context(state, memory)
decision = model.decide(context, tools)
result = execute(decision) # the harness acts, not the model
state = verify_and_update(result)The model decides; the harness executes, observes, and feeds back the results. This pattern of reasoning and acting in a loop is the foundation formalized by works such as ReAct (Yao et al., 2023).
And there is one non-negotiable detail: the loop requires termination criteria and budgets—maximum iterations, time, cost. An agent without limits is not autonomous; it is uncontrollable.
The Model Is Not the Agent
An LLM, by itself, receives text and produces text. It does not read your database, run your tests, or remember what happened yesterday. Agent capabilities emerge from the complete system: model + tools + memory + verification. When that system is poorly designed, switching to a more capable model fixes very little.
Chat vs. Agent Harness: Why It Changes the Game
When you work through chat, the agentic loop also exists... except that you are the harness. You gather context, copy and paste, execute actions, verify results, and decide whether to continue. It works for isolated tasks, but it has clear limits:
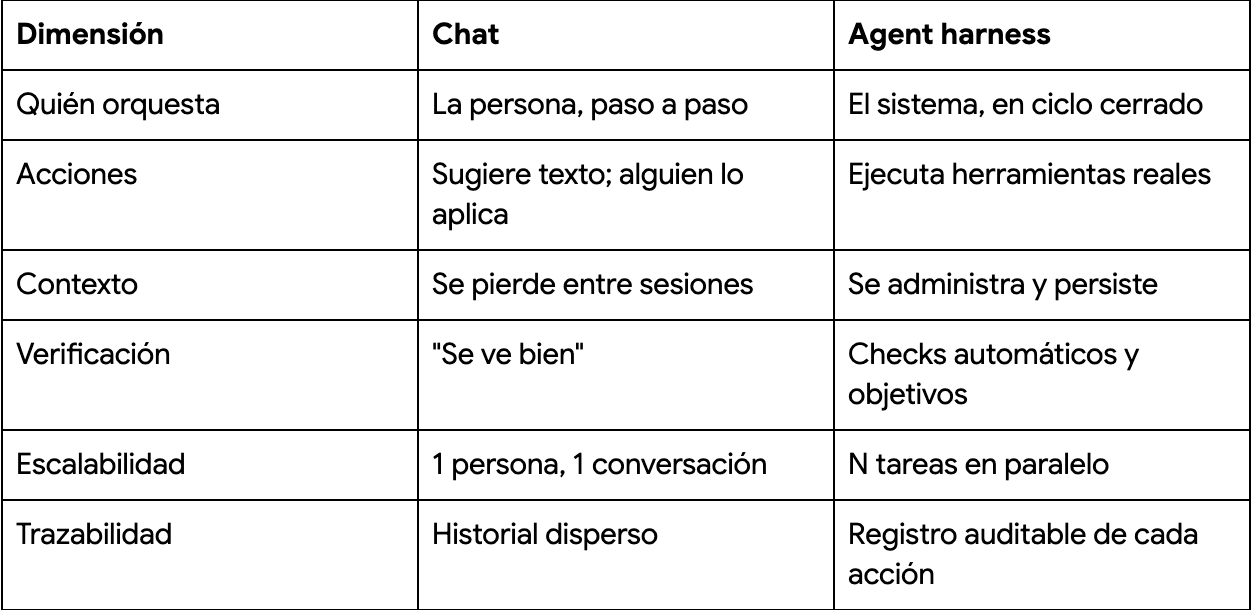
The fundamental difference is this: chat optimizes a conversation; a harness optimizes an outcome.
That is why practices such as specification-driven development fit so well with agents: the specification defines what "correct" means, and the harness is the machinery that executes and verifies that contract without requiring a person to mediate every step.
Core Patterns of Every Agent Harness
Regardless of the framework you choose (or build), these patterns appear in every serious harness. Frameworks change every quarter; concepts do not.
Tools as Contracts
Tools are the agent's interface with the world: querying an API, reading files, executing code, creating a ticket. Designing them is API design: clear names, validated parameters, unambiguous descriptions, and errors that explain what went wrong and how to fix it—because the agent reads those errors and self-corrects.
Research on tool usage shows that models improve dramatically when they can delegate to external systems what they should not "guess" (Schick et al., 2023). Practical rule: an agent is only as good as its tools.
Context Engineering
The context window is a scarce resource, and its quality degrades when filled with noise. A good harness does not dump everything in "just in case": it loads information just in time, summarizes or compresses older information when tasks become long, and keeps only what is relevant to the current decision visible (Anthropic, 2025).
Context is to an agent what RAM is to a process: managing it well is the difference between smooth execution and collapse.
Memory and State Outside the Context
What matters cannot live only in the conversation. Plans, decisions, progress, and learnings must persist outside the model: files, a database, or even a simple plan.md. This enables long-running tasks, survival across restarts, and state sharing between sessions or agents, a central idea in cognitive architectures for language agents (Sumers et al., 2023).
If knowledge remains trapped in the chat, it disappears. If it lives in artifacts, it accumulates.
Reliability and Control Patterns
The previous patterns make the agent work. These make it trustworthy. And they are exactly what security and compliance teams will ask about before approving any production agent.
Automatic Verification
The highest-return pattern of all: giving the agent an objective way to determine whether what it did is correct. Executable tests, linters, schema validation, comparisons against acceptance criteria.
With verifiable feedback, the agent iterates against reality and self-corrects. Without it, it iterates against its own opinion. This is the biggest difference from chat, where verification depends on a person's attention—and fatigue.
Graduated Autonomy: Permissions and Human-in-the-Loop
Autonomy is not a switch; it is a dial. A good harness distinguishes reversible actions (read, search, suggest) from sensitive actions (writing to production, sending emails, spending money) and requires human approval for the latter.
Combined with sandboxed execution and granular tool permissions, this enables progressively greater delegation as the agent demonstrates reliability, instead of betting on full autonomy from day one.
Observability and Traceability
Every decision, every tool call, and every result should be logged. Without traces, you cannot debug an agent, measure its success rate, control costs, or audit why it did what it did.
Observability transforms the agent from a black box into a governable process: you can answer "what happened?" with evidence instead of hypotheses.
Enterprise Applications: From Pilot to Production Process
Why does this matter beyond technical teams? Because agent harness patterns are exactly what separates an interesting pilot from a reliable business process.
- Scalability: An agent with a harness can execute dozens of tasks in parallel without depending on each person's prompting skills. Process knowledge lives in the system, not in individuals.
- Consistent quality: Verification loops produce repeatable results. A code migration, ticket triage process, or data quality check meets the same standard at 3 PM and 3 AM.
- Cost reduction: Automation is no longer limited to "generating text" and extends to complete multi-step processes: support, test generation and execution, data reconciliation, documentation updates.
- Governance and security: Built-in permissions, approvals, and auditing make AI viable in regulated environments. These are not add-ons; they are part of the design.
A concrete example: an agent that migrates services to a new framework version. With chat, a person requests code fragments and manually applies them for days. With a harness, the agent reads the repository, creates a plan in a persistent file, modifies the code, runs the test suite after each change, reverts failures, records every decision, and requests approval before merging.
Same model. Completely different value.
Best Practices for Adopting (or Building) an Agent Harness
- Evaluate frameworks by concepts, not brands. Whatever the latest popular tool may be, ask: how does it manage the loop and its limits? How does it define tools? How does it manage context and memory? What verification, permissions, and tracing capabilities does it provide? If it cannot answer these questions well, the brand does not matter.
- Start simple. A loop with three well-designed tools and automatic verification outperforms a complex multi-agent architecture without checks and with endless unreadable markdown files. Complexity should be added only when a metric justifies it (Anthropic, 2024).
- Design independently from the model. Models improve and change pricing every few months. If your harness allows you to swap them, every market improvement becomes a free upgrade for your system.
- Invest in evaluation. Define what a "successful task" means, build a test set, and measure performance before increasing autonomy. Without evaluations, scaling an agent means scaling risk.
- Treat prompts and tools as code. Version them, review them, and test them. Agent behavior is part of your system, not a loose piece of text.
Conclusion
Public discussion around AI revolves around models, but production value is determined elsewhere: in the agent harness. The bounded loop, tools as contracts, context engineering, persistent memory, automatic verification, graduated autonomy, and observability are not framework features; they are the patterns that transform a model that can converse into a system that can deliver outcomes.
Chat will continue to be useful for exploration. But when the goal is operation—with repeatable quality, control, and auditability—the harness is the difference.
Implementing a well-designed agent harness not only improves technical efficiency but also enables companies to automate complete processes, reduce costs, and scale solutions safely and sustainably. At Kranio, we have specialized teams that have implemented these types of solutions in real-world enterprise projects.
👨💻 If your company is looking to implement these kinds of solutions, contact us at 👉 www.kranio.io
References
Anthropic. (2024). Building effective agents. https://www.anthropic.com/research/building-effective-agents
Anthropic. (2025). Effective context engineering for AI agents. https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Zettlemoyer, L., Cancedda, N., & Scialom, T. (2023). Toolformer: Language models can teach themselves to use tools. arXiv. https://arxiv.org/abs/2302.04761
Sumers, T. R., Yao, S., Narasimhan, K., & Griffiths, T. L. (2023). Cognitive architectures for language agents. arXiv. https://arxiv.org/abs/2309.02427
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023). ReAct: Synergizing reasoning and acting in language models. arXiv. https://arxiv.org/abs/2210.03629
Previous Posts

CAG in LLMs: How to Reduce Latency and Costs in AI
Discover what CAG is and how it enhances speed, reduces costs, and improves consistency in LLMs. Learn when to use it and how to design efficient AI architectures.

Rate limiting: protect your API and prevent overloads
Control the traffic of your API with rate limiting. Enhance security, stability, and cost efficiency in your digital infrastructure.
