
AI-Powered Spec-Driven Coding: A Practical Guide for Teams
Spec-Driven Coding with AI: A Practical Guide for Teams
There is a question that appears more and more frequently in teams already using AI assistants for programming: if the model can write code in seconds, what exactly is the developer's job?
The easy answer is to say that programming now consists of knowing how to ask. But that answer falls short. A good prompt helps, of course. White et al. (2023) show that prompt patterns allow structuring interactions with LLMs, imposing rules, and improving the quality of the generated output. But in real-world contexts, where there is security, maintainability, technical debt, integrations, and users expecting the system not to break, asking well is not enough.
The problem is not that AI writes code. The problem is that it often does so without a sufficiently precise specification of what "correct" means.
What is Spec-Driven Coding
Spec-driven coding is a way of working where the specification stops being a decorative document and becomes the operational center of development. Before asking for code, the team makes explicit:
- What problem is to be solved.
- What observable behavior the solution must fulfill.
- What cases it must not accept.
- What architectural, security, and domain constraints cannot be violated.
- What tests will demonstrate that the implementation is correct.
In other words: the model does not receive just an intention, it receives a contract.
This difference seems small, but it changes everything. In vibe coding, the cycle is usually: ask, execute, see if it works, correct, repeat. In this approach, the cycle is: specify, convert the specification into verifiable checks, generate or modify code, run tests, review deviations, and update the specification if learning justifies it.
AI can accelerate code writing.
The specification decides whether that code belongs to the system.
Why It Matters More Now Than Before
By 2024, the study on GPT-4 by Bubeck et al. already showed that LLMs had achieved impressive capabilities for programming tasks: a model capable of solving complex problems in multiple domains, including coding, with a significant leap compared to previous generations (Bubeck et al., 2023). At that time, the conclusion was clear: software development had changed speed.
Two years later, in 2026, that feeling became even more intense. Models are faster, tools are better integrated into the IDE, and code generation has gone from being a curiosity to becoming an everyday part of many teams' workflows.
But speed is not direction.
When a tool can produce a plausible implementation almost immediately, the bottleneck shifts from writing to validation. The silent risk is accepting code that compiles, passes a superficial test, and seems reasonable, but does not respect a business rule, does not follow the actual architecture, omits an edge case, or introduces a decision that no one asked for.
That is where specification becomes an engineering practice, not a ceremony.
TDD as a Precedent
This approach does not come out of nowhere. It has a clear debt to Test-Driven Development.
Beck (2002) formulated TDD as a discipline where the developer advances by first writing a failing test, then the minimal code to make it pass, and finally refactoring. The underlying idea remains powerful: before building, we make an expectation explicit.
The difference is that with AI, that expectation needs to expand. A single isolated unit test is no longer enough. Often we also need to specify API contracts, domain invariants, data constraints, security policies, performance limits, architecture conventions, and acceptance criteria readable by business.
TDD taught us not to trust the programmer's memory.
This practice teaches us not to trust the model's statistical intuition.
Multi-Agent AI and Testing
Multi-agent frameworks reinforce this idea. Chat Dev proposes specialized agents that collaborate in phases such as design, coding, and testing through structured communication (Qian et al., 2024). Agent oder goes in a similar direction: it separates roles like programmer, test designer, and test executor, using iterative feedback to improve code generation (Huang et al., 2024).
These works show something relevant for real teams: when AI participates in more parts of the development cycle, coordination becomes as important as generation.
And coordination needs shared artifacts.
A good specification fulfills that role. It is not just an input for the model. It is the meeting point between product, architecture, QA, security, and development. It allows one agent to generate code, another to derive tests, another to review compliance, and a person to audit the decision without rebuilding everything from scratch.
If the prompt is a conversation, the specification is institutional memory.
Research on LLMs applied to testing also points in this direction. Wang et al. (2024) review 102 studies on using LMs in software testing and show that the most representative tasks include test case preparation and program repair. That is, AI can greatly help produce tests, expand scenarios, and find paths a team might overlook.
But that does not mean we can delegate quality judgment.
A suite generated from a poor specification only automates an incomplete understanding. A suite generated from an ambiguous specification can even give a false sense of security: many green lights, little real guarantee.
That is why order matters:
- First, define the expected behavior.
- Then, derive tests and checks.
- After that, generate or modify the code.
- Finally, review whether the solution meets the specification and whether the specification was good enough.
AI can participate in each step, but it should not erase the boundary between "this works" and "this is what we needed to build."
Spec-driven coding in practice
A workflow can be as simple as this:
1. Write a small, concrete spec
Not an eternal document. A useful specification for development should fit in the working context and answer operational questions:
- Business objective.
- Included and excluded scope.
- System states.
- Expected inputs and outputs.
- Validation rules.
- Known errors.
- Acceptance criteria.
- Technical constraints.
Practical example: if the team needs to add volume discounts to a B2B checkout, the spec should not just say "apply discounts to large customers." It should say: "if a company buys 50 or more licenses, apply 10% discount; if it buys 200 or more, apply 18%; the discount does not stack with promotional coupons; the total must be stored in cents as an integer; every new rule must be covered by unit and integration tests." In figure 1 we can see a tangible example of the prompt.
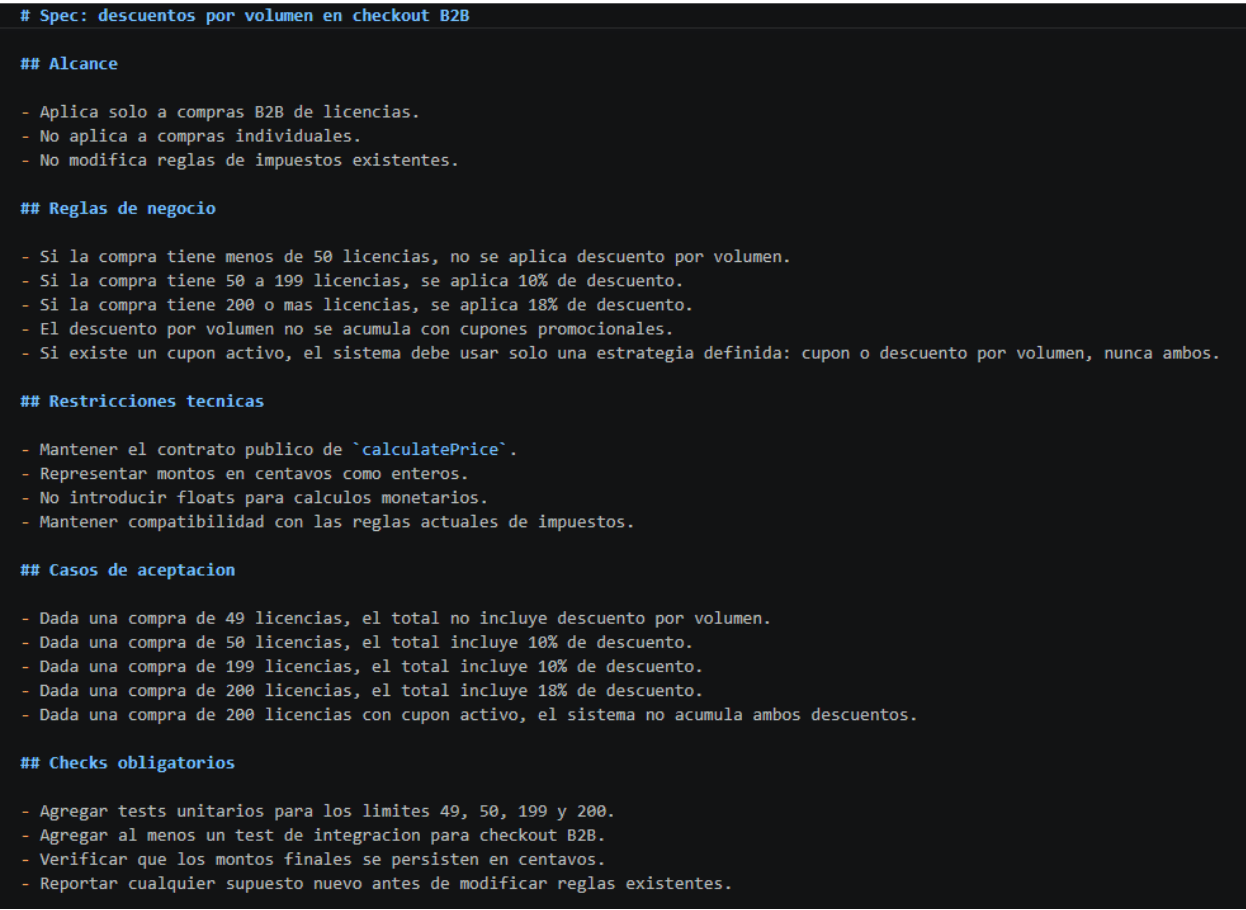
2. Convert the spec into verifiable examples
Every important rule should have at least one example. If the system calculates prices, we need cases with discounts, taxes, rounding, and exceptions. If we process applications, we need valid states, valid transitions, and role-based permissions.
AI can help propose those examples, but the team must review them as they would review requirements.
3. Generate, critique, and update
Instead of "create this feature," the prompt should say: implement this feature complying with this specification, without changing these contracts, using these patterns, maintaining compatibility with these tests, and explaining any new assumptions.
Here, prompt patterns are useful: they help frame role, format, verification, constraints, and operational reasoning steps (White et al., 2023). But the value is not in decorating the prompt; it is in reducing the surface of ambiguity.
Practical example: the prompt to the agent could be: "Implement the volume discount rule defined in pricing-spec.md. Do not change the public contract of calculatePrice. Keep amounts in cents, add tests for the 49, 50, and 200 license cases, and before editing, check if there are any existing coupon rules in the pricing module." Figure 2 shows the result of this update exercise.
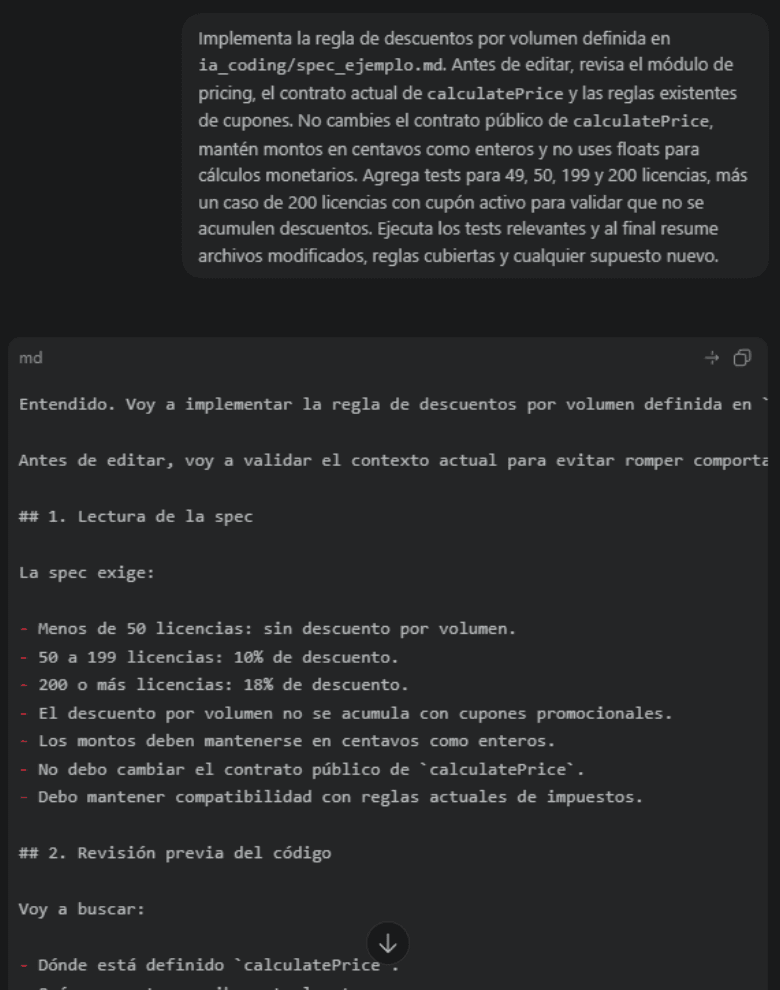
A healthy practice is to ask the assistant to look for contradictions between the spec, tests, and code. Not to replace human review, but to make the first round of friction cheaper.
Useful questions:
- What rule in the spec is not covered by tests?
- What implemented behavior does not appear in the spec?
- What assumption did you make without confirmation?
- What case could break this solution?
- What part of the code contradicts the existing architecture?
A specification is not set in stone. If a new rule, technical constraint, or product decision emerges during implementation, that information must go back into the document. Otherwise, knowledge gets trapped in the chat, the diff, or someone's head.
And then we're back to the same old problem: the team loses context.
4. Turn the spec into an agent skill
When a specification is no longer experimental and starts repeating across multiple tickets, it's worth turning it into a reusable skill or instruction for the agent. Instead of copying the same context into every conversation, the team documents the procedure, domain rules, relevant files, mandatory checks, and exit criteria in a stable artifact that the agent can invoke automatically.
This ensures operational knowledge doesn't depend on chat memory. If every pricing, authentication, reporting, or integration change must meet certain invariants, the skill can remind the agent how to analyze the problem, which paths to review, which tests to run, and what decisions cannot be made without human validation.
The spec describes what "correct" means for a feature. The skill turns that criterion into recurring agent behavior.
Practical example: if pricing changes every week, the team can turn that spec into a skill called pricing-rules. The user doesn't need to paste the same explanation into every ticket. For example, using Codex, they can ask it to use /skill-creator to create a skill with the expected flow, as shown in figure 3. The result will be a skill the agent can reuse.
In that skill, the team documents that Codex must read docs/pricing-spec.md, review src/pricing, validate coupon compatibility, run the pricing suite, and report any new assumptions before modifying code. Then, in a future ticket, it's enough to say something like: "Use the pricing-rules skill to implement this discount change." Codex loads those instructions automatically and works with the correct context from the start.
Application in companies
In companies, this approach matters because the real cost of software isn't just in writing it. It's in maintaining it, auditing it, integrating it with other systems, and changing it without breaking critical processes.
When the specification is connected to tests, acceptance criteria, and technical constraints, AI can accelerate repetitive tasks without leaving the team in the dark. This improves efficiency, reduces rework, and makes it easier to scale development across multiple teams, agents, or vendors.
It also has a business benefit: it allows discussing a feature based on verifiable evidence. Product can review whether the expected behavior is covered, QA can derive scenarios, architecture can validate boundaries, and development can implement with less ambiguity.
Best practices and recommendations
The uncomfortable promise of this approach is that it doesn't make AI seem more magical. It does the opposite: it makes it more governable.
That can feel less spectacular than writing a sentence and seeing a complete application appear. But in teams building serious software, spectacle is not the goal. The goal is to be able to answer difficult questions:
- Why was it implemented this way?
- What requirement does this part cover?
- What test proves it works?
- What risk are we accepting?
- What decision needs a human review?
When those answers exist, AI stops being a box of surprises and becomes a production capability under technical control.
Conclusion
The next stage of development with AI will not be defined solely by more capable models. It will be defined by teams capable of specifying better.
Spec-driven coding is not about writing documents out of nostalgia. It is about giving AI a clear enough framework so that its speed does not destroy the team's judgment.
Implementing spec-driven coding not only improves technical efficiency but also allows companies to optimize their processes, reduce costs, and scale solutions safely and sustainably. At Kraneo, we have specialized teams that have implemented this type of solution in real enterprise projects.
If your company is looking to implement this type of solution, you can contact us at www.kranio.io.
References
Beck, K. (2002). Test-driven development: By example. Three Rivers Institute. Local material: TDD.pdf. Equivalent public reference: https://www2.cs.uh.edu/~rsingh/documents/software_design/TDD.pdf
Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., Lee, P., Lee, Y. T., Li, Y., Lundberg, S., Nori, H., Palangi, H., Ribeiro, M. T., & Zhang, Y. (2023). Sparks of artificial general intelligence: Early experiments with GPT-4. arXiv. https://arxiv.org/abs/2303.12712. Local material: 2303.12712v5.pdf
Huang, D., Zhang, J. M., Luck, M., Bu, Q., Qing, Y., & Cui, H. (2024). AgentCoder: Multi-agent-based code generation with iterative testing and optimisation. arXiv. https://arxiv.org/abs/2312.13010. Local material: 2312.13010v3.pdf
Qian, C., Liu, W., Liu, H., Chen, N., Dang, Y., Li, J., Yang, C., Chen, W., Su, Y., Cong, X., Xu, J., Li, D., Liu, Z., & Sun, M. (2024). ChatDev: Communicative agents for software development. arXiv. https://arxiv.org/abs/2307.07924. Local material: 2307.07924v5.pdf
Wang, J., Huang, Y., Chen, C., Liu, Z., Wang, S., & Wang, Q. (2024). Software testing with large language models: Survey, landscape, and vision. arXiv. https://arxiv.org/abs/2307.07221. Local material: 2307.07221v3.pdf
White, J., Fu, Q., Hays, S., Sandborn, M., Olea, C., Gilbert, H., Elnashar, A., Spencer-Smith, J., & Schmidt, D. C. (2023). A prompt pattern catalog to enhance prompt engineering with ChatGPT. arXiv. https://arxiv.org/abs/2302.11382. Local material: 2302.11382v1.pdf
Previous Posts

Agent Harness: Design Patterns for AI Agents
Discover what an Agent Harness is and the design patterns that transform AI models into agents capable of executing tasks, verifying outcomes, and scaling business processes.

CAG in LLMs: How to Reduce Latency and Costs in AI
Discover what CAG is and how it enhances speed, reduces costs, and improves consistency in LLMs. Learn when to use it and how to design efficient AI architectures.
