
Metodología Kranio: Claves para Proyectos de Datos Exitosos
Muchas empresas desarrollan iniciativas en torno a sus datos implementando Data Lakes u otras tecnologías que permiten extraer, almacenar y organizar la máxima cantidad de datos para hacer análisis y tomar mejores decisiones. El objetivo es comprender mejor las necesidades de sus clientes, mejorar la calidad de los servicios, predecir y prevenir resultados aprovechando conocimientos significativos de toda esta información.
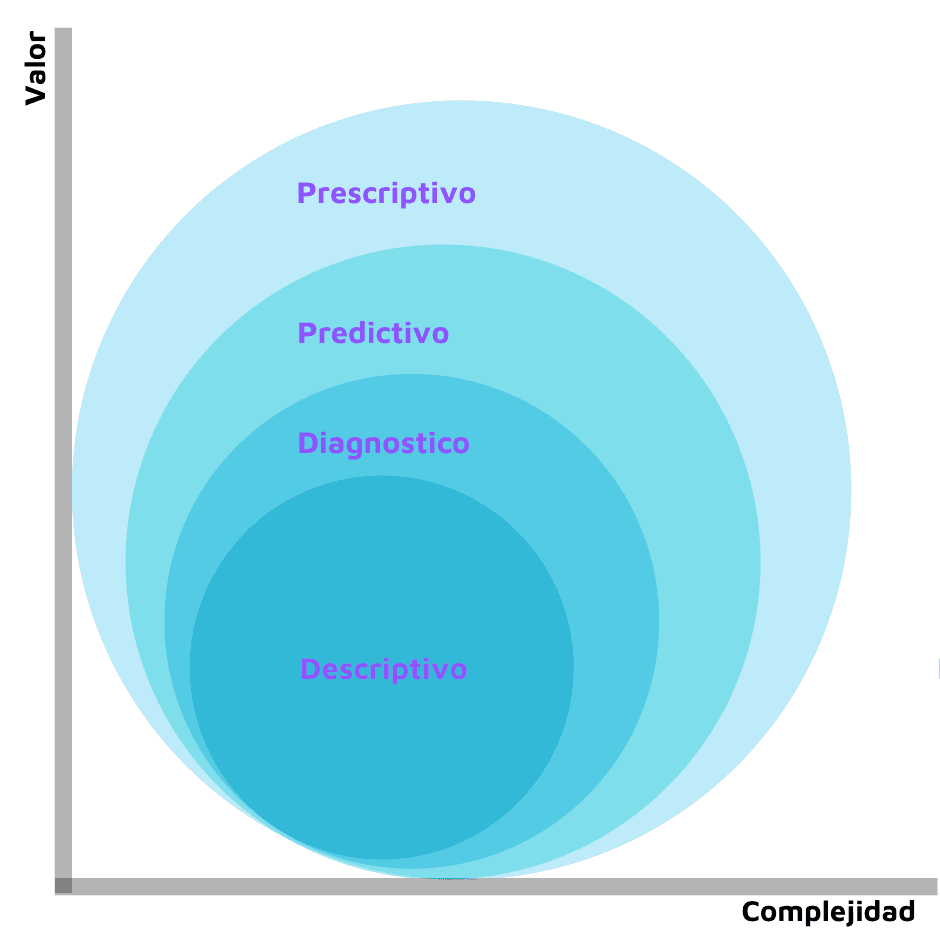
Con datos organizados y almacenados podemos procesar y analizar escenarios actuales y futuros, responder preguntas como: qué está pasando (Descriptivo), por qué está pasando (Diagnóstico), predecir qué pasará (Predictivo) y qué soluciones efectivas debes tomar para optimizar y aumentar la eficiencia (Prescriptivo).
El Data Lake es un sistema vivo, dinámico y evolutivo que recibe datos de distintas fuentes (estructurados y no estructurados), con variedad de formatos, donde los datos llegan en bruto, no optimizados ni transformados para fines específicos, por ende es importante conocer y entender las características, regulaciones y estándares que deben cumplir los datos para ser consumidos por los usuarios.
Debes siempre considerar en la implementación de un Data Lake definir un gobierno de datos. Lo primero es entender ¿Qué es un gobierno de datos? Existen muchas definiciones, para nosotros son todos los procesos, políticas y herramientas que permiten asegurar la seguridad, disponibilidad, usabilidad y calidad de los datos, garantizando que solo los usuarios autorizados puedan acceder a explorar y explotar los datos, que estos estén actualizados e íntegros, evitando el riesgo de exponer información sensible y confidencial de personas y organizaciones.
Decidir cómo proteger los datos, cómo mantener la consistencia, la integridad y precisión, y cómo los mantendremos siempre actualizados, son los puntos que cubriremos en este documento y forman parte de nuestro proceso de datos Kranio.
¿Cómo lo hacemos? - El Ingrediente Secreto
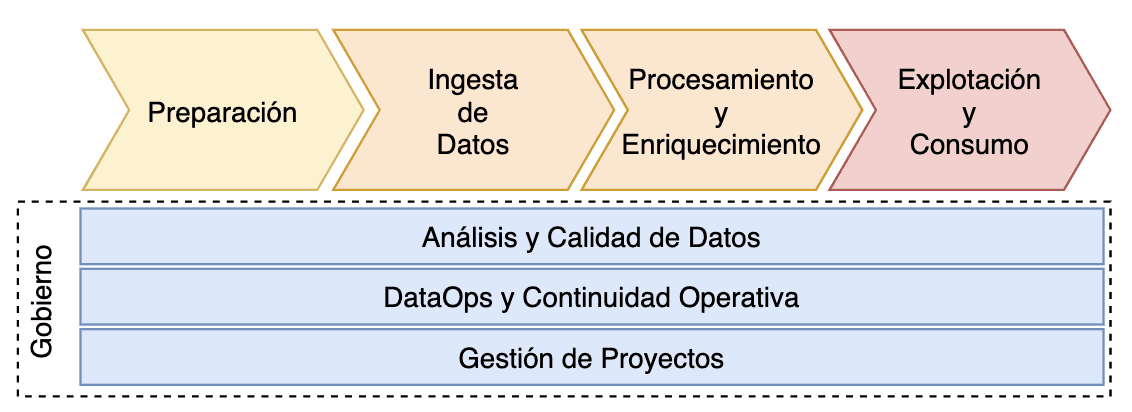
A continuación describimos en forma resumida la metodología Kranio aplicada al proceso de datos, compuesta por varias etapas no necesariamente secuenciales:
Preparación
Aquí comienza el proceso de datos. Definimos inicialmente con el negocio e incorporar un framework ágil, lideramos un design sprint organizado, en tiempo, personas que participan y su contexto, para obtener y definir los KPI's, ciclos de iteración en la construcción del producto, entender las definiciones y reglas de negocio. Concluimos con un backlog inicial de actividades que serán priorizadas durante la ejecución del proyecto.
Según el tipo de proyecto utilizamos o proponemos un framework basado en metodologías ágiles, siendo de nuestra mayor experiencia el uso de Scrum o Kanban, que permite priorizar tareas en el tiempo, definiendo rutinas de seguimiento con el negocio que nos permita dar visibilidad del producto a los interesados (recomendamos realizar un dashboard semanal).
Con respecto a la forma y herramientas de comunicación, seguimiento y documentación nuestra visión es agnóstica, nos adaptamos a lo que los clientes tengan, y en caso que no tengan ninguna, recomendamos e implementamos lo mínimo para cumplir con la expectativa y éxito del proyecto, apoyando a establecer estándares para sus proyectos de datos.
Los factores claves que consideramos en la fase de preparación de un proyecto de datos son:
- Involucrarnos con las necesidades y expectativas del negocio, entender cuál es la problemática y cuál es el valor que generará la implementación del proyecto.¿Para qué estamos haciendo el proyecto?¿Cuál es el real valor para el negocio?. Tener claridad de esto permite no sólo tomar los requerimientos del negocio, sino que también, contribuir con nuestra experiencia y hacer sugerencias y propuestas de valor durante la ejecución.
- Identificar a los interlocutores y stakeholders estableciendo con claridad el rol que cumplen dentro del proyecto.
- En un primera instancia identificar las fuentes de información que están disponibles, tanto externas como internas al Data Lake. Esto contribuye a manejar de mejor forma las expectativas, permitiéndonos levantar alertas tempranas para preparar y presentar planes de acción.
Ingesta de Datos
Tan importante como entender el problema a resolver es entender los datos que tenemos disponibles. Normalmente, los clientes tienen una manera de guardar y manipular los datos que no necesariamente hace que se almacenen de la forma correcta, o tal vez no cuente con las plataformas necesarias para hacerlo. Con eso comenzamos a definir y acordar con el cliente una arquitectura tecnológica orientada a satisfacer las necesidades del negocio actual y pensada en términos futuros de usabilidad, escalabilidad y facilidad de mantenciones.

Con la arquitectura definida, se identifican las fuentes que necesitamos integrar, la mejor forma para extraer los datos (herramienta o tecnología), la frecuencia y también evaluamos si los datos contienen estructuras que permitan identificar a las personas (PII) o si contienen datos confidenciales. Esto es importante para poder darle el tratamiento adecuado, y posteriormente ser almacenado de forma organizada y segura en el formato y estructura definida en el Data Lake. Debemos analizar la información actual disponible, para tender a reutilizar la máxima cantidad de información..
Los DataOps de Kranio comienzan la construcción de los productos digitales (código) que permitan llevar los datos desde las distintas fuentes hacia el Data Lake. Podemos usar una infinidad de herramientas y servicios que apoyan el proceso de extracción y almacenamiento, sin embargo, la creación de un pipeline de datos es vital ya que ayuda a automatizar los proceso de validación y carga de datos. Así, proporciona una herramienta centralizada de orquestación y monitoreo, incorporando seguimiento de la ejecución de un proceso, generación de alertas, registro de errores y trillas para auditoría.
Revisa cómo crear un pipeline de datos simple y robusto entre las aplicaciones legadas y el Data Lake en este video
Checklist que debes asegurar en esta etapa:
Define Estandares:
- Establece cuáles son los lenguajes de programación, repositorios de código, librerías, servicios de nube, herramientas de orquestación, monitoreo, gestión y auditoría.
- Genera el código paramétrico, es decir, nunca dejes código en estático dentro de los programas, usa archivos/tablas de configuración.
- Usa Nomenclatura estandarizada de los buckets y archivos almacenados
- Define el formato como almacenaremos los datos en las capas de transformación y consumo.
- En caso de que el proyecto requiera definir un Modelo de Datos idealmente este no debe estar orientado a un requerimiento específico, debemos pensar en la escalabilidad, en un modelo robusto que permita sentar las bases para futuros requerimientos, no tan sólo el específico del proyecto.
- Los productos deben tener puntos de validación que permitan garantizar que, aparte de terminar correctamente, se generarán datos cuadrados y consistentes.
Genera procesos de monitoreo y auditoría:
- Provee trazabilidad de todas las ejecuciones (exitosas y fallidas)
- Registra todas las acciones de capturas, transformaciones y salidas de datos
- Provee información suficiente que permita minimizar el tiempo de análisis ante eventuales fallas.
- Provee un repositorio de log centralizado y de fácil acceso que nos permita dar solución ante un problema.
Asegura la calidad de los productos:
- La entrega de los productos debe incluir las evidencias del respectivo control de calidad realizado. Garantizamos no sólo que un proceso se ejecuta, sino que se ejecuta bien y con el resultado esperado.
- Genera la evidencia de la cuadratura de los datos generados, considerando evidencia de qué se cuadró y bajo cuál escenario y condiciones fue generada.
- Datos confiables con validaciones y cuadraturas automazidas con alta cobertura de monitoreo, evita que ante cualquier error o descuadratura se cuestione la credibilidad del producto digital. Tu mejor aliado es entregar un trabajo certificado, libre de errores, consistente, garantizado.
- Productos pensados en su continuidad operativa, disponiendo de todos los recursos para fácil entrega y toma de control por el equipo de operación.
- Productos automatizados de punta a punta evita intervenciones manuales que ponen en riesgo la continuidad operativa.
Todo lo anterior nos permitirá, además de certificar el trabajo, que todas las implementaciones tengan una misma directriz y forma de hacer las cosas, y logramos optimizar el tiempo de construcción, mejorar la calidad y claridad del entendimiento y la trazabilidad de cada parte del proceso.
Procesamiento y enriquecimiento de los datos
Ya con los datos en el Data Lake en forma segura y organizada, establecemos dentro del marco de trabajo los procedimientos y transformaciones para pasar de datos almacenados en forma cruda, a información utilizable por los clientes.
Sabiendo que los datos se obtienen de múltiples fuentes que pueden ser poco confiables, es vital poder tener un proceso de análisis de la calidad y usabilidad de los datos. Este proceso puede iniciarse en forma manual, no obstante debe terminar en procesos automatizados con herramientas. El rol de los arquitectos e Ingenieros de datos es vital ya que nos ayudan a evaluar y detectar si es requerida más información para definir un dataset confiable que permite realizar los análisis requeridos. También ayudan a identificar los datos faltantes para la creación correcta del dataset fundamentales en el desarrollo del proyecto, y a eliminar los datos incorrectos, duplicados ó incompletos.
En este proceso los especialistas implementan las mejores prácticas de proyectos de datos (BigData), organizan la información a través de varias categorías y clasificaciones según permitan los datos, cada subconjunto se analiza de manera independiente y realizan las transformaciones de estructuración o de enriquecimiento de los datos adicionando nuevas columnas, datos calculados que son generados a partir de los datos existentes o incorporando información de otras fuentes externas. Los datos finales pueden ser disponibilizados al usuario a través de un modelo relacional en un datawarehouse , una vista para acceso a los datos o un archivo de consumo.
Aprovechar la “inteligencia” que aportan los datos es rol de los cientista de datos el cual es está encargado de analizar escenarios simulados para realizar predicciones, aportar modelamiento matemático, análisis estadístico, técnicas de machine learning, desarrollar análisis predictivo, clustering, regresión, reconocimiento de patrones que permitan traer nuevos datos que enriquecen el proyecto y da más valor a los clientes.
La seguridad de la información y el correcto acceso de los usuarios al Data Lake debe estar establecido en el gobierno de datos donde se identifica la propiedad, formas de acceso, reglas de seguridad para datos confidenciales, historial de datos, fuentes de origen y otros.
Explotación, consumo y continuidad operativa
El último aspecto es la forma en que los usuarios usarán los datos. En cuanto al consumo y explotación de los datos generados, el foco debe estar enlas necesidades del usuario de negocio, con el que co-diseñamos una propuesta de solución que cumpla con los requerimientos y parámetros definidos en la fase de preparación. Este trabajo incluye la revisión del levantamiento de los requisitos definidos en la preparación del proyecto y la selección de una plataforma adecuada a sus necesidades de visualización como Tableau, PowerBi, AWS QuickSight u otro. Debes crear un storyboard para las distintas categorías de usuarios y un preparar un diseño personalizado y eficiente para el entendimiento de los datos que están siendo presentados.
Un buen trabajo de descubrimiento y exploración de datos definirá la base del objetivo de tener una plataforma de visualización de datos auto-servicio, donde los usuarios obtienen insights para mejorar la gestión y toma de decisiones, de forma inteligente y respaldada por información confiable. Por ejemplo, ve como una empresa ‘escucha’ lo que dicen sus clientes en formularios, contact centers y redes sociales y lo usa para mejorar el servicio al cliente
La calidad y confiabilidad de los datos es de vital importancia, ya que si los datos llegan mal a plataforma, existirán errores en las visualizaciones y los dashboards y los archivos generados no brindarán la información que requiere el cliente. Debes poner énfasis en este punto ya que el análisis corresponde al 70% del tiempo total que se requiere para crear un buen Dashboard.
Bueno, no todo termina en el entregable de un dashboard o archivo para los clientes, debes pensar también en el futuro, es decir, considerar otros aspectos que son importantes:
- Continuidad operativa de los productos digitales desarrollados. La mayor parte del tiempo, la operación y monitoreo en entorno productivo estará a cargo del cliente por lo que el foco es la vida a esas personas, es decir, minimizar el tiempo de monitoreo, minimizar el tiempo que demoran en revisar las causas de un problema, minimizar el tiempo de solución de una falla.
- Escalabilidad de la solución en todas los componentes tales como infraestructura, arquitectura, junto a las herramientas que se emplearán durante el desarrollo y que permitan crecer a medida que el negocio lo requiera.
- Facilidad para trazar los eventuales problemas. Poder encontrar rápidamente información, tener un diagnóstico inicial y un plan de corrección.
- Minimizar la complejidad de los procesos para simplificar las futuras adecuaciones o mejoras.
- Todos los proyectos incluyen documentación completa que facilitan el entendimiento colectivo.
- Evita usar multiplicidad de herramientas que a la larga no dan valor al negocio.
- Genera las instancias de comunicación con el cliente que permitan hacer un traspaso efectivo y claro de todo lo realizado. Mientras más claridad tenga el cliente de todo el buen trabajo que se hizo, mayor será el grado de satisfacción, y siempre considera el perfil del interlocutor (área operaciones, negocio y otros).
Conclusión
Asegura el éxito en el diseño, implementación y desarrollo de un proyecto de datos aplicando una metodología de proyectos de datos. En este artículo te mostramos la metodología Kranio aplicada y refinada en decenas de proyectos de datos en varios países. Si aplicas esta Metodología tienes mayor probabilidad de cumplir las expectativas y evitar errores que pueden arruinar el proyecto.
Otro aspecto fundamental que debes asegurar es la participación del usuario del negocio. Son ellas y ellos quienes consumen los datos para mejorar las decisiones. Desde el inicio, en cada etapa, equipos robustos, alineados y bien comunicados entregan mejores proyectos.
Quieres revisar tu metodología o implementar esta Metodología para proyectos exitosos?
¿Listo para llevar tus proyectos de datos al siguiente nivel?
En Kranio, aplicamos una metodología comprobada que asegura el éxito en cada etapa de tus iniciativas de datos. Nuestro equipo de expertos te guiará desde la planificación hasta la implementación, garantizando resultados efectivos y alineados con tus objetivos de negocio. Contáctanos y descubre cómo podemos colaborar en el éxito de tu empresa.
Entradas anteriores

Agent harness: patrones de diseño para agentes de IA
Descubre qué es un Agent Harness y los patrones que permiten convertir modelos de IA en agentes capaces de ejecutar tareas, verificar resultados y escalar procesos empresariales.

Spec-driven coding con IA: guia practica para equipos
Descubre cómo el Spec-Driven Coding ayuda a los equipos a usar IA para desarrollar software con más control, mejores pruebas y menos deuda técnica.
