
Serie Data Science (3 de 3): Carga y Cuadratura de Datos en la Nube con AWS
Las organizaciones dependen de sus datos para poder tomar decisiones inteligentes, esta toma de decisiones tiende a ser realizada por altos cargos y equipos de gerencia. Para poder entender la data esta debe llegar en formato de reporte o similar, de modo que sea fácil de interpretar, existen muchas alternativas para generar reportabilidad, sin embargo, lo ideal es construir reportes automáticos.
Sobre este artículo
Este es el tercer artículo de la serie sobre Data Science Parte 1 y Parte 2
Cada artículo se puede leer independiente del orden ya que el contenido está separado por distintas etapas que, a pesar de tener una fuerte conexión se pueden entender individualmente. Cada publicación busca dar luz sobre los procesos que se llevan a cabo en la industria y que podrían ayudarte a decidir si tu organización puede contratar un servicio para migrar tus datos a la nube o aprender acerca de cómo funciona el desarrollo de este tipo de proyectos en caso de que seas estudiante. Hay algunos conceptos que se dan por sabidos, los cuales son explicados en la serie por lo que se recomienda dar una lectura completa en caso de que algunas palabras claves suenen desconocidas.
Uno de los procesos fundamentales en los proyectos de Data Science es la carga de datos, en este articulo veremos en que consisten los procesos de carga para visualizar y cómo se realiza cuadratura de datos para asegurar que el producto desarrollado está devolviendo los datos esperados por el negocio.
Carga de data
La carga de datos es el último paso del flujo ETL y permite habilitar los datos para visualización de datos, esta consiste en presentar los datos en un sistema de forma visual para que de esta forma los clientes puedan tomar decisiones vitales. En este caso siempre se busca que los datos a visualizar estén automatizados para que de este modo se realicen labores de transformación y limpieza de datos. Para llevar a cabo la carga de datos y la automatización de todos estos procesos existen varias herramientas, sin embargo, hoy día disponemos de la nube.
¿Por que nos podría interesar migrar a la nube?
La nube es aquella tecnología que permite almacenar, administrar y brindar acceso a toda la data de tu negocio. Más allá de que la nube permita a las organizaciones evitar invertir dinero en equipos y data centers propios para poder gestionar la información de su negocio. La nube permite a las empresas acceder a una amplia variedad de aplicaciones y servicios que resultan fundamentales y muy poderosos a la hora de modernizar el negocio, para de este modo aprovechar todas las virtudes de la tecnología y convertir eso en una ventaja competitiva que saque adelante su negocio.
En las plataformas Cloud podemos encontrar multitud de servicios únicos que permiten extraer todo el potencial digital a tu organización, entre ellos se encuentran herramientas para gestionar y desarrollar herramientas Big Data.
La carga en la nube
Una vez son realizados los procesos de transformación los resultados son estos son enviados a la nube dentro de una zona en un Bucket del Datalake. Al tratarse del último proceso de transformación sus resultados son almacenados en una provision-zone para que sea cargado a un sistema de Data Warehouse Cloud como puede ser AWS Redshift o AWS Glue con Athena mediante un Crawler. De modo que los datos pasen de provision-zone a estar disponibles particionados en una tabla estructurada listos para ser consultados por un sistema de reportabilidad y de esta forma llevar a cabo una visualización de datos y comenzar a realizar practicas de Business Intelligent. Las herramientas que nos podemos encontrar para manejar procesos de big data, son una de las siguientes:
AWS Glue
Se trata de un servicio de AWS que permite implementar procesos ETL con el objetivo de categorizar, limpiar, enriquecer y mover los datos. Rastrea las fuentes de datos y carga los datos estructurados en un destino. Al utilizarlo con un Crawler y Athena construye un catalogo interpretando los tipos de datos. Los catálogos son repositorios de metadatos con formatos y esquemas de datos denominado Data Catalog.
Glue Crawler
Los Crawler analizan la data para crear la metadata que permite a Glue y los servicios como Athena ver la información almacenada en S3 como bases de dato con tablas. Al dejar disponible la data en un formato estructurado se puede crear el Glue Data Catalog, en cada ejecución del flujo ETL se genera y actualiza el Glue Data Catalog.
Athena
Es una herramienta para análisis de datos. Se utiliza para procesar consultas SQL complejas en poco tiempo. Es un servicio serverless por lo que no requiere de administrar la infraestructura. Por lo que solo se paga por consulta realizada. Con este servicio se puede consultar la data desde plataformas como Tableau.
Consultas SQL: Las consultas SQL son aquellos procesos computacionales en los que se solicita información a una base de datos estructurada y esta devuelve la información indicada.
Serverless: Son aquellas plataformas o sistemas que funcionan sin necesidad de tener habilitado un servidor para funcionar, si no que son ejecutadas solo al consumirse, de este modo permitiendo ahorrar poder de computo y servidores que no se utilizan.
Redshift
Es un servicio de Data Warehouse en la nube de AWS que permite realizar consultas SQL para big data. Basta con crear un cluster para comenzar a trabajar el Data Warehouse de Redshift. Esta pensado para trabajar con cantidades gigantescas de datos. Permite procesar los datos en forma paralela con el fin de ahorrar tiempo.
Cluster: Los clusters consisten en uno o varios servidores que se compartan como uno solo para llevar a cabo un proceso que requiera poder de computo.
Big data: Son denominados Big data todos aquellos procesos en que se procesan grandes cantidades de información.
Tableau
Es una herramienta de visualización de datos para análisis de datos y Business Intelligent. Toma los datos desde sistemas que se puedan consultar como Athena o Redshift y permite visualizar los datos con múltiples herramientas, y múltiples vistas.
Visualización: La visualización consiste en tomar la data estructurada del negocio para generar gráficos o representaciones visuales de los datos que permiten poder entender el negocio en forma rápida y simple, de tal modo que se puedan tomar decisiones inteligentes.
Business Intelligent: La inteligencia de negocios consiste en interpretar y analizar de la forma más simple y rápida mediante el uso de tecnología y diversos procesos para que el negocio pueda tomar decisiones vitales.
Cuadratura de datos
Una vez son cargados los datos en un Data Warehouse estos se encuentran disponibles para consumir, sin embargo, se haya trabajado o no con data sensible, se deben realizar tareas de cuadratura para asegurar que el resultado final no haya alterado los valores esperados y asegurar de esta manera que se esté llegando a los valores correctos.
Las tareas de cuadratura son procesos en donde se busca llegar a los mismos resultados entre los datos a los que llega el usuario con su solución manual y a los que se llega en la carga o en algunos de los procesos de transformación.
Es posible que en algunos casos en lugar de contrastar contra un resultado construido por el usuario o el cliente, se tengan que construir manualmente la fuente de datos contra la que cuadrar tomando los datos desde la zona de ingesta.
Alternativas para cuadrar
Para realizar una cuadratura existen muchas alternativas distintas. Se puede utilizar Excel o librerías de lenguajes de programación como Python, entre ellas encontramos Pandas y PySpark.
Podemos cuadrar los valores de algunas columnas obteniendo la sumatoria total o la cantidad de elementos, también podemos realizar los mismos cálculos o filtros específicos con los resultados transformados y confirmar que se llegué a los mismos valores.
El proceso sería similar al siguiente:
- Descargamos los datos originales desde la zona de ingesta.
- Leemos la fuente desde alguna herramienta.
- Realizamos los cálculos, transformaciones, filtros, tablas dinámicas, etc. Para llegar a los mismos resultados que el script.
- Comparamos ambas fuentes y compartimos los resultados con el equipo.
Es fundamental que la fuente de datos que se utilice para las transformaciones y para el resultado manual sea la misma. De no ser así, difícilmente se llegaran a los mismos resultados.
Cuadrar con Excel
Para cuadrar de esta manera basta con abrir nuestra fuente de datos con Microsoft Excel o alguna herramienta similar.
A continuación procedemos a calcular una serie de datos que tengan relación con el archivo de transformación, por ejemplo: si sabemos que en la transformación relacionamos datos, deberíamos validar agrupando y filtrando esos datos en concreto, además de los valores numéricos que sean relevantes.
Realizamos una tabla dinámica para validar que las agrupaciones que generamos den el mismo resultado que se ve en la siguiente imagen para los filtros y los valores:
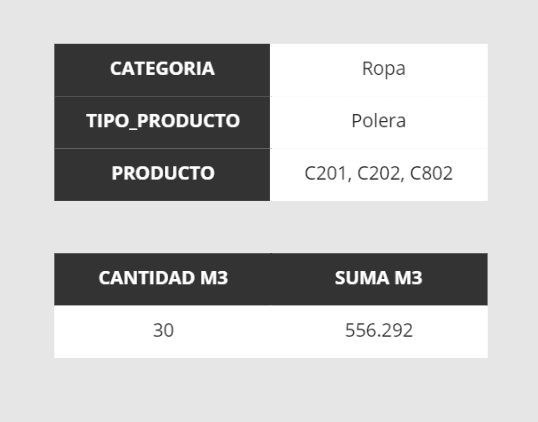
Cuadrar en PySpark
PySpark es una librería de Python que permite realizar transformaciones a Big Data con Spark. A continuación se describen una serie de scripts que se pueden realizar en procesos de cuadratura de datos.
Obtener suma de agrupación
groupBy(). El cual nos permite indicar las columnas que se utilizarán para agrupar seguido del tipo de calculo que se realizará sobre las agrupaciones, en este caso una suma con sum().
dataframe.groupBy('CATEGORIA','TIPO_PRODUCTO').sum('m3').sort('CATEGORIA').show()
Recordemos que los dataframe son un formato de dato que puede ser manejado mediante código de programación mediante librerías especializadas en Data Analysis como son por ejemplo: Pandas y PySpark.
""" Output
+-----------------+---------------+------------------+
|CATEGORIA | TIPO_PRODUCTO| sum(m3)|
+-----------------+---------------+------------------+
| null| null| 31|
| Ropa| Polera| 556.291|
| Ropa| Poleron| 10154.277|
| Tecnología| Ipad| 20905.502|
+-----------------+---------------+------------------+
"""
Obtener cantidad de agrupación
groupBy() como en el caso anterior o podemos utilizar filtros para contrastar que los valores obtenidos coincidan contando distintos indicadores.
count_ropa = df.where(df.TIPO_PRODUCTO=='Ropa').count()
count_tecnologia = df.where(df.TIPO_PRODUCTO=='Tecnología').count()
print('Ropa:', count_ropa, 'Tecnología:', count_tecnologia)
""" Output
Ropa: 2314 Tecnologia: 232
"""
Solucionar errores de cuadratura
Es extremadamente común que una vez revisados los datos estos no calcen, eso NO siempre significará que las transformaciones estén mal realizadas, puede ocurrir también que la fuente de datos es distinta o que al ingresar los datos a un sistema para cuadrarlos estemos interpretando mal algunos valores numéricos, etc. Deberemos identificar en que casos los valores no están coincidiendo, proceder a aislar los mismos para analizarlos y contrastarlos.
Enfocar detección de errores
A continuación corregiremos un error de cuadratura con ejemplos reales, en este caso corregir un conteo de valores que no coincide. Una alternativa útil para identificar la fuente de este error es obtener una agrupación de una columna utilizada en la transformación filtrando por el valor que no calza, de este modo podemos contar los valores con el objetivo de exportar este resultado y poder contrastar el archivo en Excel.
df = df.select('group_column').where(df.TIPO_PRODUCTO == 'ROP').groupBy('group_column').count()
df.show()
""" Output
+-----------------+---------------+
|group_column | count() |
+-----------------+---------------+
| 32413EH200| 1|
| 30413EH300| 2|
| 30413EH400| 1|
| 33313EH500| 3|
+-----------------+---------------+
"""
# Exportamos el archivo para compararlo en el Excel
test.write.csv('grp_matnr', sep=';')
Creamos una pestaña en Excel donde agregamos el resultado del CSV que exportamos y del mismo calculo del script pero realizado en Excel, cada uno con sus columnas correspondientes, de la siguiente manera:
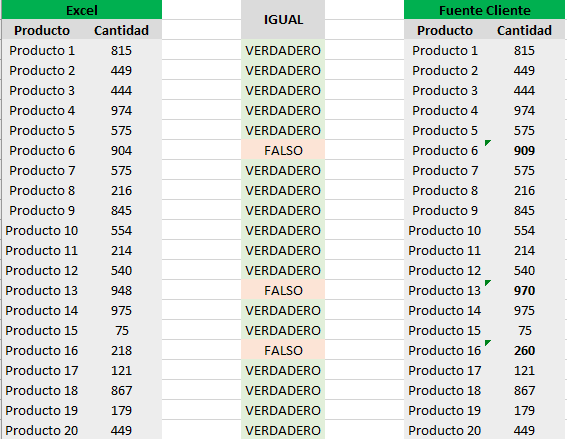
Esto directamente nos mostrará que valores son distintos al de nuestro Script y nos permitirá enfocar nuestro análisis en unos pocos datos, en lugar de en miles de ellos.
Transformar valores que alteran las columnas
Por otro lado, podemos encontrarnos con el caso de que algunos valores de las columnas están alterando los cálculos del script o están inhabilitando su calculo desde las cuadraturas. Para corregir esto podemos generar scripts que transformen la data resultante o la data ingesta. Por ejemplo a continuación se identifico que el uso de comillas dobles en algunos de los valores ocasionaba problemas, por lo que se remueve desde el script.
df = dataframes_dict['main']
# Diccionario con los tipos de dato de cada columna
columns_types_dict = {
#...
'product_desc': StringType(),
}
# Iteramos por cada columna indicada en el diccionario
for column_name, column_type in columns_types_dict.items():
...
# Removemos la comilla doble de todos los String
elif column_type == StringType():
df = df.withColumn(
column_name,
regexp_replace(column_name, '"', '')
)
Corregir separador en transformación
En ocasiones la separación que posee el archivo de salida no coincide con la herramienta que utilizamos para cuadrar. Afortunadamente corregir la separación del documento generado es muy simple de hacer al momento de exportar en el script.
test.write.csv('export', sep=';')
Igualmente es posible corregir la separación buscando todos los valores donde aparezca el separador y reemplazar en todos los casos por otro. Para estas tareas puede ser muy útil una herramienta como Notepad++.
Corregir suma de valores
En ocasiones al obtener los datos de sistemas de gestión como SAP con los datos crudos podemos encontrarnos con datos que debemos transformar para volverlos legibles desde el Data Warehouse y para que puedan cuadrarse, teniendo que convertir formatos de la siguiente manera:
410.500,210 ⇒ 410500.210
Script para corregir formato decimal
df_double_obj = ['peso_neto', 'cantidad', 'us$_fob', 'us$_cif', 'us$_flete', 'cantidad_aux', 'espesor', 'volumen_m3', 'densidad']
for column_name in df_double_obj:
if column_name not in data.columns:
continue
data[column_name] = data[column_name].apply(lambda x: str(x).replace('.','') if ',' in str(x) else x)
data[column_name] = data[column_name].apply(lambda x: str(x).replace(',','.') if ',' in str(x) else x)
En ocasiones no podemos utilizar el script para cuadrar y deberemos corregir el archivo manualmente. Por ejemplo en Excel los valores numéricos que tienen mal formato de decimales no permite cuadrar las sumatorias, esto es debido a que los números son mal interpretados alterando el valor real de los resultados.
Al igual que en el caso anterior es posible modificar todos estos tipo de formato con reemplazos en herramientas como Notepad++.
¿Listo para optimizar la carga y validación de tus datos en la nube?
En Kranio, contamos con expertos en soluciones de datos que te ayudarán a implementar procesos eficientes de carga y cuadratura utilizando herramientas de AWS, asegurando la calidad y disponibilidad de tu información para la toma de decisiones estratégicas. Contáctanos y descubre cómo podemos impulsar la transformación digital de tu empresa.
Entradas anteriores

Agent harness: patrones de diseño para agentes de IA
Descubre qué es un Agent Harness y los patrones que permiten convertir modelos de IA en agentes capaces de ejecutar tareas, verificar resultados y escalar procesos empresariales.

Spec-driven coding con IA: guia practica para equipos
Descubre cómo el Spec-Driven Coding ayuda a los equipos a usar IA para desarrollar software con más control, mejores pruebas y menos deuda técnica.
