
CAG in LLMs: How to Reduce Latency and Costs in AI
If you are working with language models in production, you probably already know that awkward moment: the user asks a question, the application queries a vector database, fetches document snippets, puts them into the prompt, and only then does the model respond. It works, yes. But each of those stages adds latency, costs, and points where something can go wrong.
Along the way, I came across an approach worth knowing: Cache-Augmented Generation (CAG).
In this blog, I want to tell you what CAG is, why it is gaining traction, and in which scenarios it can change your life. And yes, I also want to be honest: a good RAG is still absolutely necessary for many cases. It’s not about replacing, it’s about adding one more tool to the toolbox.
What is CAG, simply put?
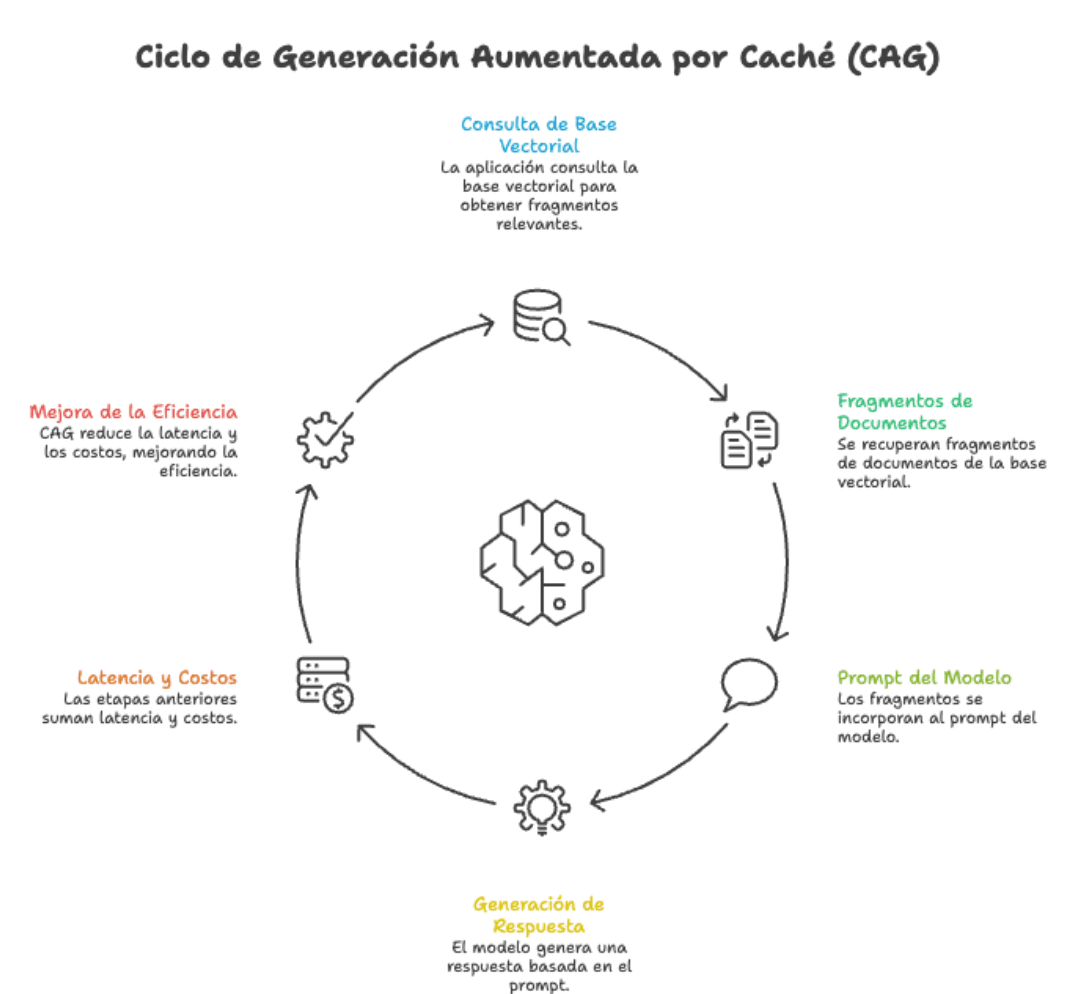
CAG starts from a straightforward idea: instead of searching for information every time a question arrives, we preload all the relevant knowledge within the model’s context once and save the internal state of the LLM (what is known as KV cache, or key-value attention cache).
When a user query arrives, the model already "has all the documentation in its head." There is no vector search, no result ranking, no risk of fetching the wrong chunk. Just: query → answer.
The technique was formalized in the paper "Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks" and leverages a reality that until recently did not exist: modern language models with significantly extended context windows that today allow us to fit hundreds of pages of text without breaking a sweat.
The benefits of CAG
1. Speed you can feel
This is the point that impacts production the most. By eliminating the retrieval stage, responses are almost instantaneous. Complex question-answering tasks that used to take 94.35 seconds now take only 2.33 seconds. A speed increase of up to 40x in certain benchmarks.
For an internal chatbot, an onboarding assistant, or an automated help desk, that difference between "wait three seconds" and "immediate response" is the difference between a product people use and one they abandon after the second query.
2. Simpler architecture, fewer parts to maintain
With traditional RAG you need: a vector database, an embeddings model, a chunking strategy, an ingestion pipeline, a reranker (ideally), and all the observability around that. Each component is a place where something can fail.
CAG, on the other hand, reduces everything to: preprocessed documentation + KV cache + LLM. It eliminates the need for vector databases, embedding stores, or external retrieval services. Less infrastructure, lower fixed costs, less surface to debug on a Tuesday at 11 PM.
3. More consistent answers
One of the classic problems of RAG is that the same question, asked in two different ways, can fetch different chunks and give different answers. With CAG that disappears: all queries are answered against the same complete context, which greatly improves consistency. For cases like internal policies, product documentation, or regulatory answers, this is gold.
4. Zero retrieval errors
RAG can fail silently: it fetches the wrong chunk, the model responds confidently, and no one notices until a user reports it. CAG eliminates that entire category of errors. If the answer is in the preloaded documents, the model has it available at all times. It does not depend on a similarity algorithm having ranked well.
5. More natural multi-document reasoning
When a question requires connecting information from several documents (multi-hop reasoning), RAG struggles: it has to fetch the correct chunks from each source and hope the model relates them well. CAG, by having the entire corpus present, reasons about the knowledge as an integrated whole. This is especially noticeable in complex questions like "how does policy X relate to procedure Y when scenario Z applies?"
6. Predictable costs
By eliminating calls to embedding services and vector databases, and by leveraging the cache, the costs per query go down and become much more predictable. The big cost is paid once, when precomputing the KV cache, and then each query is comparatively inexpensive.
Where does CAG shine?
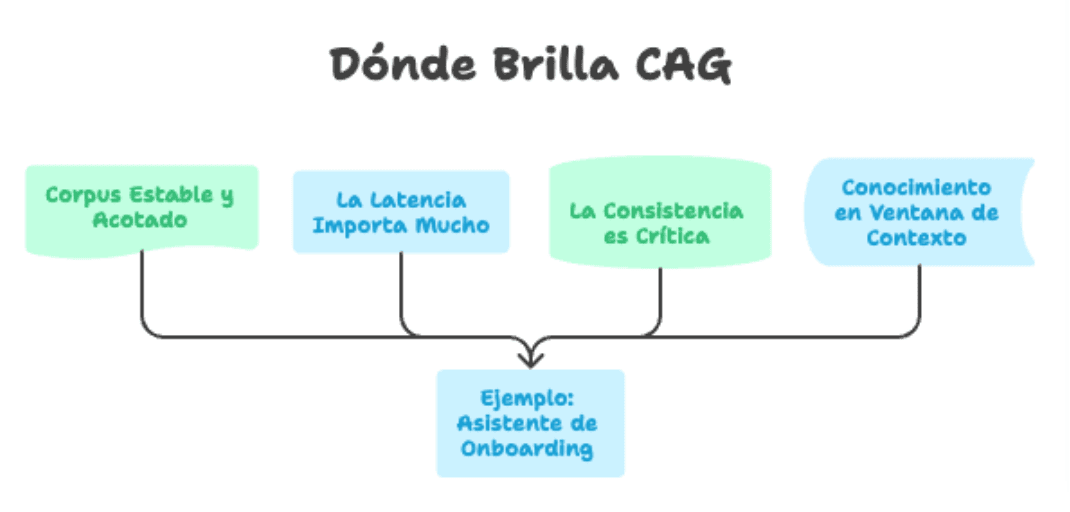
Not all use cases are the same. CAG stands out especially when:
- The corpus is stable and bounded. Product manuals, internal policies, technical documentation of a specific version, regulatory frameworks, business FAQs.
- Latency matters a lot. Real-time assistants, voice bots, conversational experiences where every second counts.
- Consistency is critical. Legal answers, compliance, first-level support, official corporate information.
- The knowledge fits within the context window. With models that today support 128k, 200k, or even 1M tokens, this covers a huge number of real cases.
In a typical onboarding assistant project for a company, for example, all relevant documentation probably does not exceed 80-100 pages. That fits comfortably in the context of current models, and the usage profile is ideal: stable knowledge, many repetitive queries, need for fast response.
But beware: a good RAG is still necessary
Here comes the honest part. CAG is not a silver bullet, and at Kranio we believe ignoring RAG would be a strategic mistake. There are scenarios where RAG is not only still relevant but clearly the best option:
When the knowledge is dynamic
If your information changes every day, product catalogs, inventories, recent support tickets, news, operational data. CAG forces you to recalculate the KV cache every time, which nullifies its speed advantages. RAG, with its ability to index incrementally, is made for this.
When the corpus is massive
CAG depends on everything fitting in the context. If your knowledge base is millions of documents, gigabytes of text, complete customer histories, there is no context window big enough. RAG remains the right tool to navigate oceans of information and bring exactly what matters.
When you need fine traceability
RAG gives you, by design, the ability to say "this answer comes from this chunk of this document." That traceability is key in regulated cases, audits, and any scenario where citing the source is not optional.
When the domain has many rare questions
If your users make very varied queries about very specific niches of a huge corpus, RAG with a good chunking strategy and a decent reranker will outperform CAG, which would be loading a lot of irrelevant context for each query.
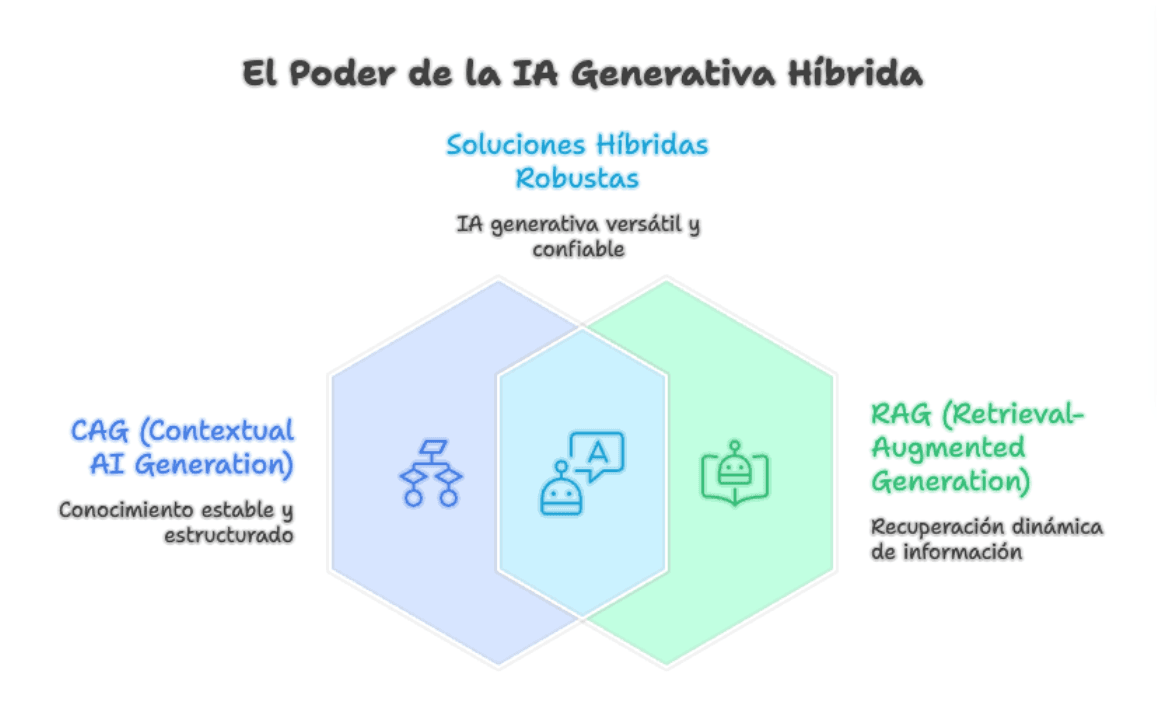
The future: hybrid architectures
The real discussion is not "CAG or RAG." It is "what combination of both best solves my problem?"
We are already seeing hybrid patterns where a base context is preloaded with CAG (policies, processes, stable documentation) and RAG is used for specific cases: searching historical tickets, consulting transactional data, bringing freshly updated information. The best of both worlds.
A well-designed RAG with smart chunking, domain-tuned embeddings, reranking, and observability remains the foundation on which robust generative AI solutions are built. CAG is an evolution that enhances certain cases, not an excuse to lower the bar in retrieval design.
In conclusion
CAG is a powerful tool when your knowledge is stable, bounded, and latency matters. It gives you speed, consistency, less infrastructure, and fewer retrieval errors. For many conversational products and internal assistants, it can be exactly the missing piece.
But the right question is not "CAG or RAG?". It is "what is the architectural design that best solves the business problem, considering how knowledge changes, how long the context lasts, and what the user expects?".
And answering that question well with engineering criteria, not trends, is precisely the kind of challenge that we at Kranio love to solve together with our clients.
Are you evaluating generative AI for your company?
At Kranio we design and implement generative AI solutions tailored to each client's real context, from architecture strategy (RAG, CAG, hybrids) to productive deployment and operation. If you want to talk about how to apply this in your organization, let's talk.
Previous Posts
AI Prompt Injection: How to Secure Your Infrastructure
Discover what Prompt Injection in AI is, how the latest attacks work, and what strategies to implement to protect agents, copilots, and LLM-based systems.
RabbitMQ (the king of queues) or Apache Kafka (the event streaming giant)?
Learn the differences between RabbitMQ and Apache Kafka, their use cases, and the 2026 updates to choose the best messaging solution for your architecture.
